
Perceptron AI Roundup : biais, vision par ordinateur et action des vagues – TechCrunch
La recherche dans le domaine de l’apprentissage automatique et de l’IA, désormais une technologie clé dans pratiquement toutes les industries et entreprises, est beaucoup trop volumineuse pour que quiconque puisse tout lire. Cette colonne, Perceptron (anciennement Deep Science), vise à rassembler certaines des découvertes et des articles récents les plus pertinents – en particulier, mais sans s’y limiter, l’intelligence artificielle – et à expliquer pourquoi ils sont importants.
Cette semaine dans AI, une nouvelle étude révèle comment le biais, un problème courant dans les systèmes d’IA, peut commencer par les instructions données aux personnes recrutées pour annoter les données à partir desquelles les systèmes d’IA apprennent à faire des prédictions. Les co-auteurs constatent que les annotateurs reprennent des modèles dans les instructions, ce qui les conditionne à contribuer des annotations qui deviennent ensuite surreprésentées dans les données, biaisant le système d’IA vers ces annotations.
Aujourd’hui, de nombreux systèmes d’IA «apprennent» à donner un sens aux images, aux vidéos, au texte et à l’audio à partir d’exemples qui ont été étiquetés par des annotateurs. Les étiquettes permettent aux systèmes d’extrapoler les relations entre les exemples (par exemple, le lien entre la légende « évier de cuisine » et une photo d’un évier de cuisine) aux données que les systèmes n’ont pas vues auparavant (par exemple, des photos d’éviers de cuisine qui n’étaient pas inclus dans les données utilisées pour « enseigner » le modèle).
Cela fonctionne remarquablement bien. Mais l’annotation est une approche imparfaite – les annotateurs apportent des biais à la table qui peuvent saigner dans le système formé. Par exemple, des études ont montré que l’annotateur moyen est plus susceptible d’étiqueter des phrases en anglais vernaculaire afro-américain (AAVE), la grammaire informelle utilisée par certains Noirs américains, comme toxiques, les principaux détecteurs de toxicité de l’IA formés sur les étiquettes pour voir AAVE comme disproportionnellement toxique.
Il s’avère que les prédispositions des annotateurs ne sont peut-être pas les seules responsables de la présence de biais dans les étiquettes de formation. Dans une étude pré-imprimée de l’Arizona State University et de l’Allen Institute for AI, les chercheurs ont cherché à savoir si une source de biais pouvait résider dans les instructions écrites par les créateurs d’ensembles de données pour servir de guides aux annotateurs. Ces instructions comprennent généralement une brève description de la tâche (par exemple, « Étiquetez tous les oiseaux sur ces photos ») ainsi que plusieurs exemples.
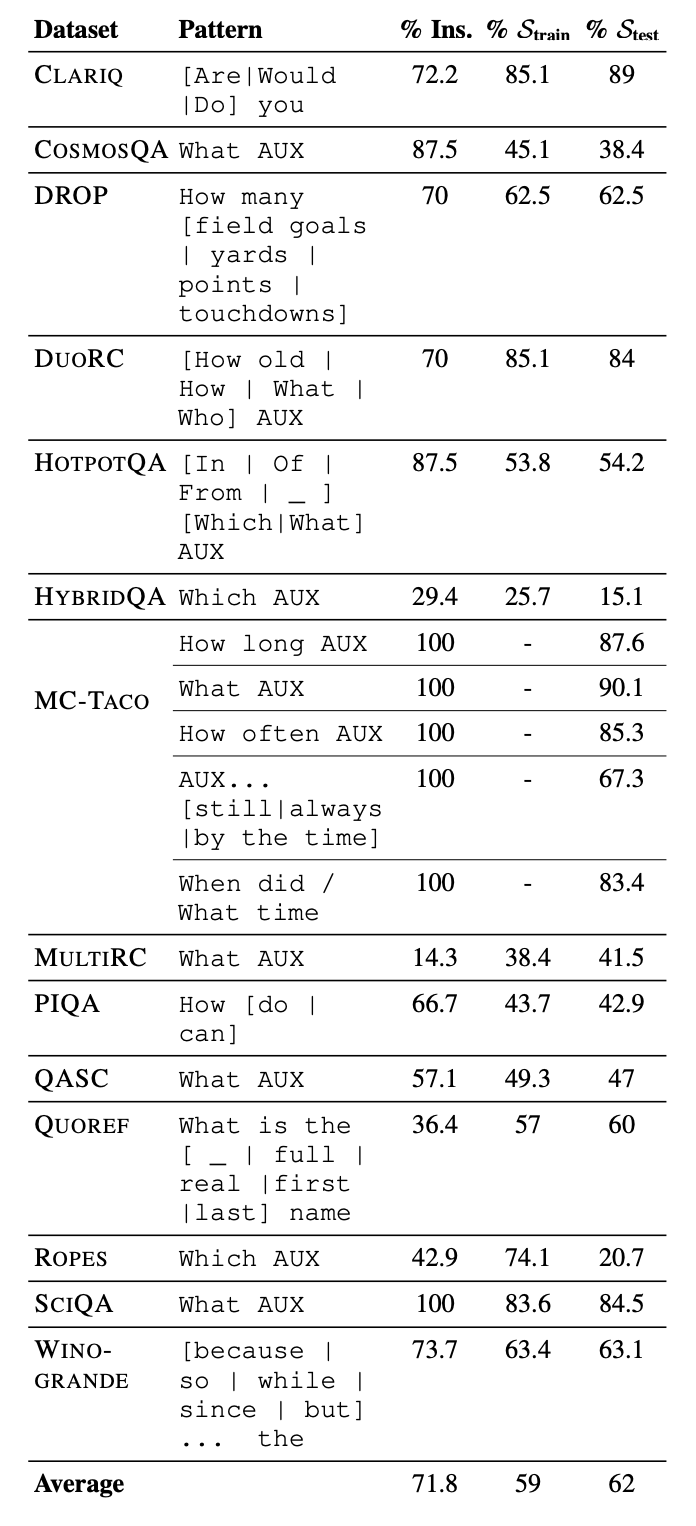
Crédits image : Parmar et al.
Les chercheurs ont examiné 14 ensembles de données «de référence» différents utilisés pour mesurer les performances des systèmes de traitement du langage naturel ou des systèmes d’IA capables de classer, résumer, traduire et autrement analyser ou manipuler du texte. En étudiant les instructions de tâche fournies aux annotateurs qui travaillaient sur les ensembles de données, ils ont trouvé des preuves que les instructions incitaient les annotateurs à suivre des modèles spécifiques, qui se propageaient ensuite aux ensembles de données. Par exemple, plus de la moitié des annotations dans Quoref, un ensemble de données conçu pour tester la capacité des systèmes d’IA à comprendre quand deux ou plusieurs expressions font référence à la même personne (ou chose), commencent par la phrase « Quel est le nom », un expression présente dans un tiers des instructions pour l’ensemble de données.
Le phénomène, que les chercheurs appellent « biais d’instruction », est particulièrement troublant car il suggère que les systèmes formés sur des données d’instruction/annotation biaisées pourraient ne pas fonctionner aussi bien qu’on le pensait initialement. En effet, les co-auteurs ont constaté que le biais d’instruction surestime les performances des systèmes et que ces systèmes échouent souvent à généraliser au-delà des modèles d’instruction.
La doublure argentée est que les grands systèmes, comme le GPT-3 d’OpenAI, se sont avérés généralement moins sensibles au biais d’instruction. Mais la recherche rappelle que les systèmes d’IA, comme les gens, sont susceptibles de développer des biais à partir de sources qui ne sont pas toujours évidentes. Le défi insoluble consiste à découvrir ces sources et à atténuer l’impact en aval.
Dans un article moins sérieux, des scientifiques originaires de Suisse ont conclu que les systèmes de reconnaissance faciale ne sont pas facilement trompés par des visages réalistes édités par l’IA. Les «attaques de morphing», comme on les appelle, impliquent l’utilisation de l’IA pour modifier la photo d’une pièce d’identité, d’un passeport ou d’une autre forme de pièce d’identité dans le but de contourner les systèmes de sécurité. Les co-auteurs ont créé des « morphes » à l’aide de l’IA (StyleGAN 2 de Nvidia) et les ont testés contre quatre systèmes de reconnaissance faciale de pointe. Les morphes ne présentaient pas de menace significative, affirmaient-ils, malgré leur apparence réaliste.
Ailleurs dans le domaine de la vision par ordinateur, les chercheurs de Meta ont développé un « assistant » d’IA qui peut se souvenir des caractéristiques d’une pièce, y compris l’emplacement et le contexte des objets, pour répondre aux questions. Détaillé dans un article préimprimé, le travail fait probablement partie de l’initiative Project Nazare de Meta pour développer des lunettes de réalité augmentée qui tirent parti de l’IA pour analyser leur environnement.
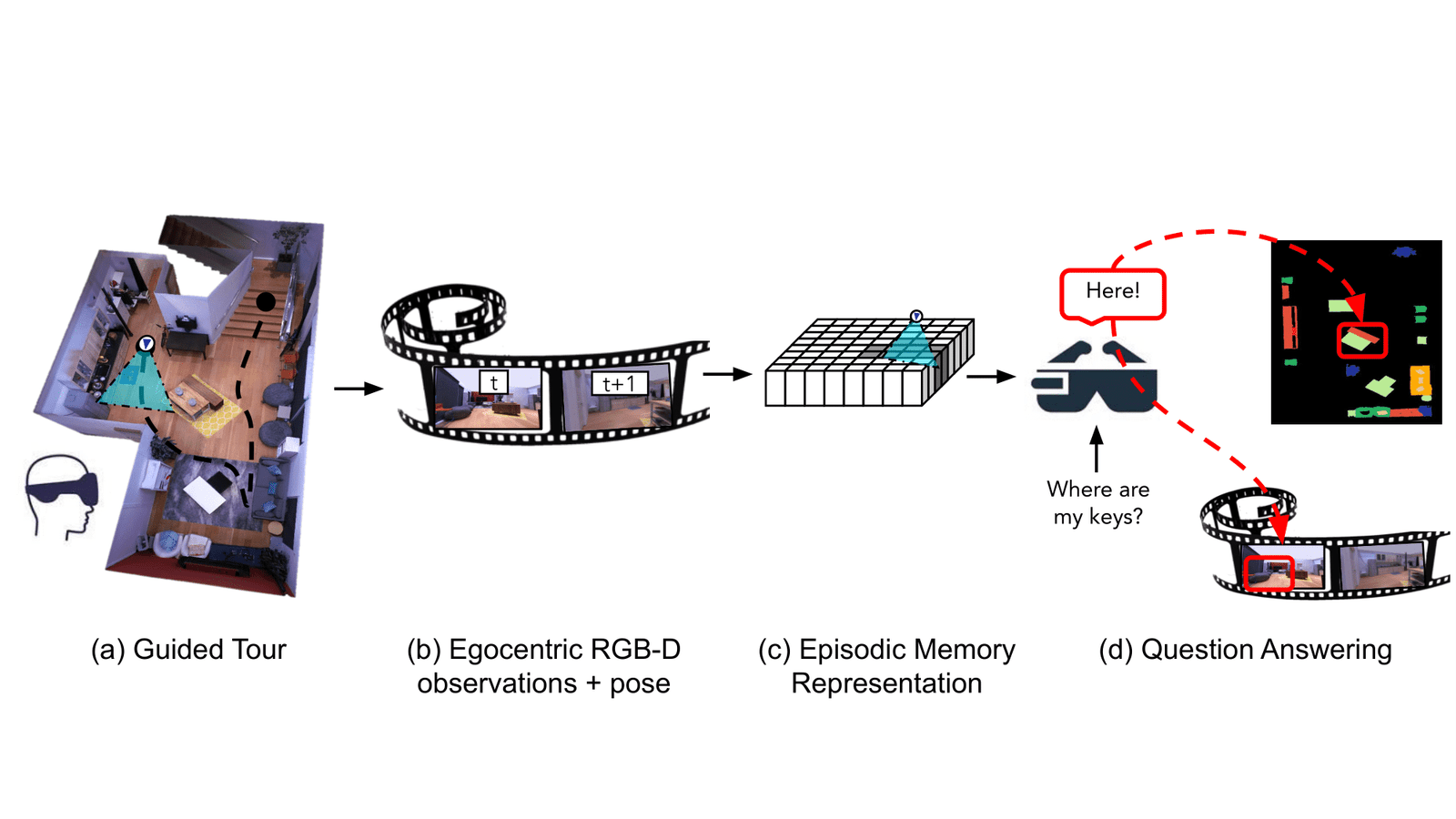
Crédits image : Méta
Le système des chercheurs, qui est conçu pour être utilisé sur n’importe quel appareil porté sur le corps équipé d’une caméra, analyse les séquences pour construire « des mémoires de scène sémantiquement riches et efficaces » qui « encodent des informations spatio-temporelles sur les objets ». Le système se souvient de l’endroit où se trouvent les objets et du moment où ils sont apparus dans la séquence vidéo, et de plus place les réponses aux questions qu’un utilisateur pourrait poser sur les objets dans sa mémoire. Par exemple, lorsqu’on vous demande « Où avez-vous vu mes clés pour la dernière fois ? », le système peut indiquer que les clés se trouvaient sur une table d’appoint dans le salon ce matin-là.
Meta, qui aurait l’intention de sortir des lunettes AR entièrement équipées en 2024, a télégraphié ses plans pour l’IA « égocentrique » en octobre dernier avec le lancement d’Ego4D, un projet de recherche sur l’IA de perception égocentrique à long terme. La société a déclaré à l’époque que l’objectif était d’enseigner aux systèmes d’IA, entre autres tâches, à comprendre les signaux sociaux, comment les actions des porteurs d’appareils AR pourraient affecter leur environnement et comment les mains interagissent avec les objets.
Du langage et de la réalité augmentée aux phénomènes physiques : un modèle d’IA a été utile dans une étude du MIT sur la façon dont elles se brisent et quand. Bien que cela semble un peu obscur, la vérité est que les modèles de vagues sont nécessaires à la fois pour construire des structures dans et près de l’eau, et pour modéliser la façon dont l’océan interagit avec l’atmosphère dans les modèles climatiques.

Crédits image : MIT
Normalement, les vagues sont grossièrement simulées par un ensemble d’équations, mais les chercheurs ont formé un modèle d’apprentissage automatique sur des centaines d’instances de vagues dans un réservoir d’eau de 40 pieds rempli de capteurs. En observant les vagues et en faisant des prédictions basées sur des preuves empiriques, puis en les comparant aux modèles théoriques, l’IA a aidé à montrer où les modèles ont échoué.
Une startup est née de la recherche à l’EPFL, où le doctorat de Thibault Asselborn. La thèse sur l’analyse de l’écriture manuscrite est devenue une application éducative à part entière. À l’aide d’algorithmes qu’il a conçus, l’application (appelée School Rebound) peut identifier les habitudes et les mesures correctives en seulement 30 secondes d’un enfant écrivant sur un iPad avec un stylet. Ceux-ci sont présentés à l’enfant sous forme de jeux qui l’aident à écrire plus clairement en renforçant les bonnes habitudes.
« Notre modèle scientifique et notre rigueur sont importants et nous distinguent des autres applications existantes », a déclaré Asselborn dans un communiqué de presse. « Nous avons reçu des lettres d’enseignants qui ont vu leurs élèves s’améliorer à pas de géant. Certains élèves viennent même avant le cours pour s’entraîner.

Crédits image : université de Duke
Une autre nouvelle découverte dans les écoles élémentaires concerne l’identification des problèmes d’audition lors des dépistages de routine. Ces dépistages, dont certains lecteurs se souviendront peut-être, utilisent souvent un appareil appelé tympanomètre, qui doit être opéré par des audiologistes formés. S’il n’y en a pas, par exemple dans un district scolaire isolé, les enfants ayant des problèmes d’audition peuvent ne jamais obtenir l’aide dont ils ont besoin à temps.
Samantha Robler et Susan Emmett de Duke ont décidé de construire un tympanomètre qui fonctionne essentiellement de lui-même, en envoyant des données à une application pour smartphone où elles sont interprétées par un modèle d’IA. Tout élément inquiétant sera signalé et l’enfant pourra faire l’objet d’un examen plus approfondi. Ce n’est pas un remplacement pour un expert, mais c’est beaucoup mieux que rien et peut aider à identifier les problèmes d’audition beaucoup plus tôt dans les endroits sans les ressources appropriées.