
Amazon SageMaker Inférence sans serveur Inférence d’apprentissage automatique sans se soucier des serveurs | Services Web Amazon

|
En décembre 2021, nous avons introduit Amazon SageMaker Serverless Inference (en préversion) en tant que nouvelle option dans Amazon Sage Maker pour déployer des modèles d’apprentissage automatique (ML) pour l’inférence sans avoir à configurer ou à gérer l’infrastructure sous-jacente. Aujourd’hui, je suis heureux d’annoncer qu’Amazon SageMaker Serverless Inference est désormais généralement disponible (GA).
Différents cas d’utilisation d’inférence ML posent des exigences différentes sur votre infrastructure d’hébergement de modèles. Si vous travaillez sur des cas d’utilisation tels que la diffusion d’annonces, la détection de fraude ou des recommandations de produits personnalisées, vous recherchez très probablement une inférence en ligne basée sur une API avec des temps de réponse aussi courts que quelques millisecondes. Si vous travaillez avec de grands modèles ML, comme dans les applications de vision par ordinateur (CV), vous aurez peut-être besoin d’une infrastructure optimisée pour exécuter l’inférence sur des tailles de charge utile plus importantes en quelques minutes. Si vous souhaitez exécuter des prédictions sur un jeu de données entier ou sur des lots de données plus volumineux, vous pouvez exécuter une tâche d’inférence par lots unique à la demande au lieu d’héberger un point de terminaison de diffusion de modèle. Et que se passe-t-il si vous avez une application avec des modèles de trafic intermittents, comme un service de chatbot ou une application pour traiter des formulaires ou analyser des données à partir de documents ? Dans ce cas, vous souhaiterez peut-être une option d’inférence en ligne capable de provisionner et d’adapter automatiquement la capacité de calcul en fonction du volume de demandes d’inférence. Et pendant les périodes d’inactivité, il devrait pouvoir désactiver complètement la capacité de calcul afin que vous ne soyez pas facturé.
Amazon Sage Makernotre service de ML entièrement géré, propose différentes options d’inférence de modèle pour prendre en charge tous ces cas d’utilisation :
Inférence sans serveur Amazon SageMaker plus en détail
Dans de nombreuses conversations avec des praticiens du ML, j’ai répondu à la demande d’une option d’inférence ML entièrement gérée qui vous permet de vous concentrer sur le développement du code d’inférence tout en gérant pour vous tout ce qui concerne l’infrastructure. SageMaker Serverless Inference offre désormais cette facilité de déploiement.
En fonction du volume de demandes d’inférence reçues par votre modèle, SageMaker Serverless Inference provisionne, dimensionne et désactive automatiquement la capacité de calcul. Par conséquent, vous ne payez que le temps de calcul pour exécuter votre code d’inférence et la quantité de données traitées, et non le temps d’inactivité.
Vous pouvez utiliser les algorithmes intégrés de SageMakers et les conteneurs de service de framework ML pour déployer votre modèle sur un point de terminaison d’inférence sans serveur ou choisir d’apporter votre propre conteneur. Si le trafic devient prévisible et stable, vous pouvez facilement passer d’un point de terminaison d’inférence sans serveur à un point de terminaison en temps réel SageMaker sans avoir à modifier votre image de conteneur. En utilisant l’inférence sans serveur, vous bénéficiez également des fonctionnalités de SageMakers, y compris des métriques intégrées telles que le nombre d’appels, les pannes, la latence, les métriques d’hôte et les erreurs dans Amazon CloudWatch.
Depuis son lancement en avant-première, SageMaker Serverless Inference a ajouté la prise en charge du SDK Python SageMaker et du registre de modèles. SageMaker Python SDK est une bibliothèque open source pour créer et déployer des modèles ML sur SageMaker. Le registre de modèles SageMaker vous permet de cataloguer, de versionner et de déployer des modèles en production.
Nouveauté pour le lancement GA, SageMaker Serverless Inference a augmenté la limite maximale d’appels simultanés par point de terminaison à 200 (contre 50 lors de la préversion), vous permettant d’utiliser Amazon SageMaker Serverless Inference pour les charges de travail à fort trafic. Amazon SageMaker Serverless Inference est désormais disponible dans toutes les régions AWS où Amazon Sage Maker est disponible, sauf pour les régions AWS GovCloud (États-Unis) et AWS Chine.
Plusieurs clients ont déjà commencé à profiter des avantages de SageMaker Serverless Inference :
Bazaarvoice s’appuie sur l’apprentissage automatique pour modérer le contenu généré par les utilisateurs afin de permettre à nos clients une expérience d’achat transparente, rapide et fiable. Cependant, opérer à l’échelle mondiale sur une base de clients diversifiée nécessite une grande variété de modèles, dont beaucoup sont rarement utilisés ou doivent évoluer rapidement en raison d’importantes rafales de contenu. Amazon SageMaker Serverless Inference offre le meilleur des deux mondes : il évolue rapidement et de manière transparente pendant les rafales de contenu et réduit les coûts des modèles peu utilisés.. Lou Kratz, PhD, ingénieur de recherche principal, Bazaarvoice
Les transformateurs ont changé l’apprentissage automatique et Hugging Face a favorisé leur adoption dans toutes les entreprises, en commençant par le traitement du langage naturel et maintenant avec l’audio et la vision par ordinateur. La nouvelle frontière pour les équipes d’apprentissage automatique à travers le monde consiste à déployer des modèles volumineux et puissants de manière rentable. Nous avons testé Amazon SageMaker Serverless Inference et avons pu réduire considérablement les coûts des charges de travail de trafic intermittent tout en faisant abstraction de l’infrastructure. Nous avons permis aux modèles Hugging Face de fonctionner immédiatement avec SageMaker Serverless Inference, aidant ainsi les clients à réduire encore plus leurs coûts d’apprentissage automatique. Jeff Boudier, directeur de produit, Hugging Face
Voyons maintenant comment vous pouvez démarrer sur SageMaker Serverless Inference.
Pour cette démo, j’ai construit un classificateur de texte pour transformer les avis des clients e-commerce, comme J’adore ce produit ! en sentiments positifs (1), neutres (0) et négatifs (-1). J’ai utilisé l’ensemble de données Womens E-Commerce Clothing Reviews pour affiner un modèle RoBERTa à partir de la bibliothèque Hugging Face Transformers et du hub de modèles. Je vais maintenant vous montrer comment déployer le modèle formé sur un point de terminaison d’inférence sans serveur Amazon SageMaker.
Déployer le modèle sur un point de terminaison d’inférence sans serveur Amazon SageMaker
Vous pouvez créer, mettre à jour, décrire et supprimer un point de terminaison d’inférence sans serveur à l’aide de la console SageMaker, des kits SDK AWS, du kit SDK Python SageMaker, de l’AWS CLI ou d’AWS CloudFormation. Dans ce premier exemple, j’utiliserai le SDK Python SageMaker car il simplifie le flux de travail de déploiement du modèle grâce à ses abstractions. Vous pouvez également utiliser le SDK Python SageMaker pour appeler le point de terminaison en transmettant la charge utile conformément à la demande. Je vais vous montrer cela dans un instant.
Tout d’abord, créons la configuration du point de terminaison avec la configuration sans serveur souhaitée. Vous pouvez spécifier la taille de la mémoire et le nombre maximal d’appels simultanés. SageMaker Serverless Inference attribue automatiquement des ressources de calcul proportionnelles à la mémoire que vous sélectionnez. Si vous choisissez une taille de mémoire supérieure, votre conteneur a accès à davantage de vCPU. En règle générale, la taille de la mémoire doit être au moins aussi grande que la taille de votre modèle. Les tailles de mémoire que vous pouvez choisir sont 1024 Mo, 2048 Mo, 3072 Mo, 4096 Mo, 5120 Mo et 6144 Mo. Pour mon modèle RoBERTa, configurons une taille de mémoire de 5120 Mo et un maximum de cinq invocations simultanées.
import sagemaker
from sagemaker.serverless import ServerlessInferenceConfig
serverless_config = ServerlessInferenceConfig(
memory_size_in_mb=5120,
max_concurrency=5
)
Déployons maintenant le modèle. Vous pouvez utiliser le estimator.deploy() méthode pour déployer le modèle directement à partir de l’estimateur de formation SageMaker, avec la configuration du point de terminaison d’inférence sans serveur. Je fournis également mon code d’inférence personnalisé dans cet exemple.
endpoint_name="roberta-womens-clothing-serverless-1"
estimator.deploy(
endpoint_name = endpoint_name,
entry_point="inference.py",
serverless_inference_config=serverless_config
)
SageMaker Serverless Inference prend également en charge le registre de modèles lorsque vous utilisez le kit AWS SDK pour Python (Boto3). Je vais vous montrer comment déployer le modèle à partir du registre de modèles plus loin dans cet article.
Vérifions les paramètres du point de terminaison d’inférence sans serveur et l’état du déploiement. Accédez à la console SageMaker et accédez au point de terminaison d’inférence déployé :
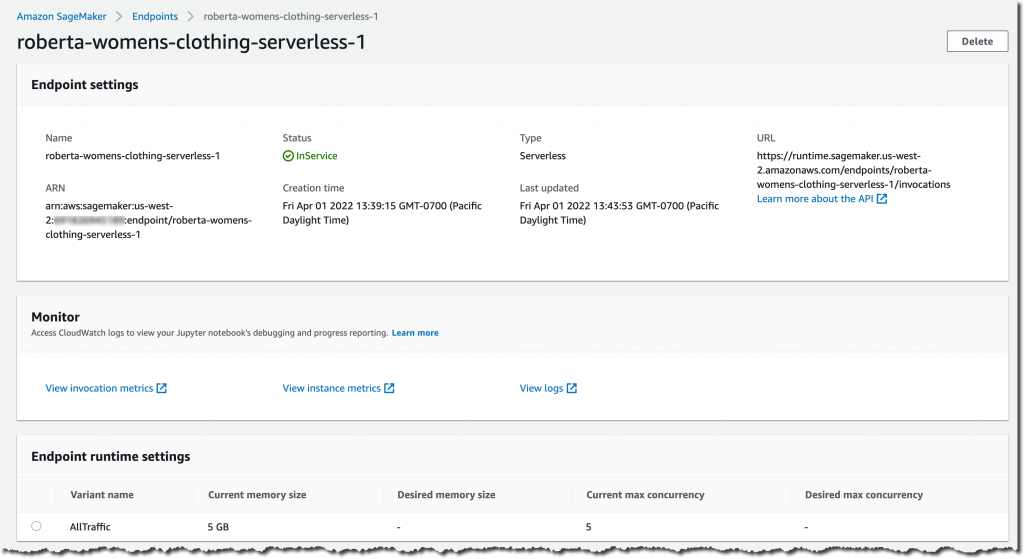
À partir de la console SageMaker, vous pouvez également créer, mettre à jour ou supprimer des points de terminaison d’inférence sans serveur si nécessaire. Dans Amazon SageMaker Studio, sélectionnez l’onglet Point de terminaison et votre point de terminaison d’inférence sans serveur pour examiner les détails de configuration du point de terminaison.
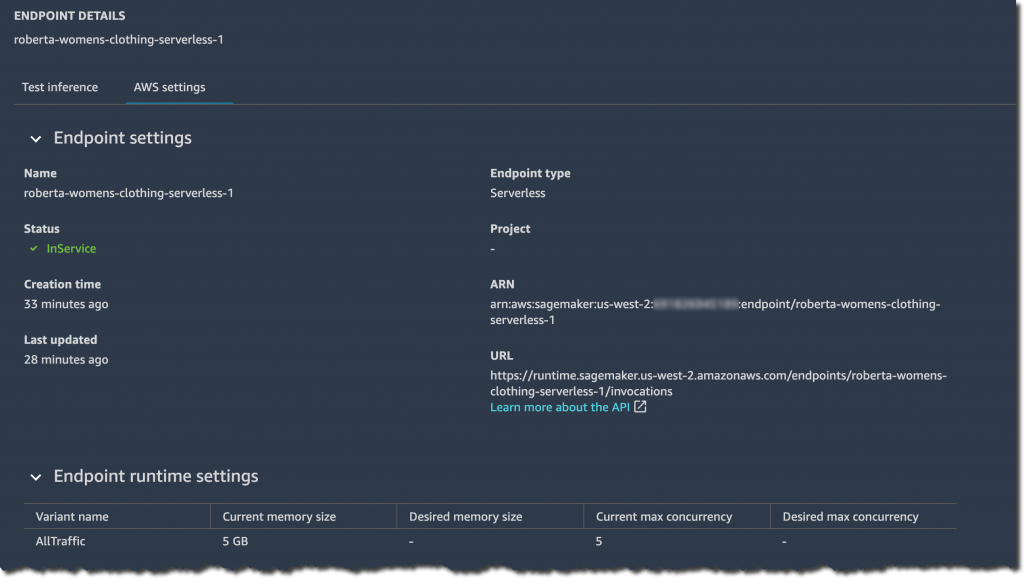
Une fois que l’état du point de terminaison s’affiche InServicevous pouvez commencer à envoyer des demandes d’inférence.
Maintenant, exécutons quelques exemples de prédictions. Mon modèle RoBERTa affiné attend les demandes d’inférence au format JSON Lines avec le texte de révision à classer comme caractéristique d’entrée. Un fichier texte JSON Lines comprend plusieurs lignes où chaque ligne individuelle est un objet JSON valide, délimité par un caractère de saut de ligne. Il s’agit d’un format idéal pour stocker des données qui sont traitées un enregistrement à la fois, comme dans l’inférence de modèle. Vous pouvez en savoir plus sur les lignes JSON et d’autres formats de données courants pour l’inférence dans le manuel du développeur Amazon SageMaker. Notez que le code suivant peut sembler différent selon le format de demande d’inférence accepté par vos modèles.
from sagemaker.predictor import Predictor
from sagemaker.serializers import JSONLinesSerializer
from sagemaker.deserializers import JSONLinesDeserializer
sess = sagemaker.Session(sagemaker_client=sm)
inputs = [
"features": ["I love this product!"],
"features": ["OK, but not great."],
"features": ["This is not the right product."],
]
predictor = Predictor(
endpoint_name=endpoint_name,
serializer=JSONLinesSerializer(),
deserializer=JSONLinesDeserializer(),
sagemaker_session=sess
)
predicted_classes = predictor.predict(inputs)
for predicted_class in predicted_classes:
print("Predicted class with probability ".format(predicted_class['predicted_label'], predicted_class['probability']))
Le résultat ressemblera à celui-ci, classant les exemples d’avis dans les classes de sentiment correspondantes.
Predicted class 1 with probability 0.9495596289634705
Predicted class 0 with probability 0.5395089387893677
Predicted class -1 with probability 0.7887083292007446
Vous pouvez également déployer votre modèle à partir du registre de modèles vers un point de terminaison SageMaker Serverless Inference. Ceci est actuellement uniquement pris en charge via le kit AWS SDK pour Python (Boto3). Laissez-moi vous présenter une autre démonstration rapide.
Déployer le modèle à partir du registre de modèles SageMaker
Pour déployer le modèle à partir du registre de modèles à l’aide de Boto3, créons d’abord un objet modèle à partir de la version du modèle en appelant le create_model() méthode. Ensuite, je transmets l’Amazon Resource Name (ARN) de la version du modèle dans le cadre des conteneurs de l’objet de modèle.
import boto3
import sagemaker
sm = boto3.client(service_name="sagemaker")
role = sagemaker.get_execution_role()
model_name="roberta-womens-clothing-serverless"
container_list =
['ModelPackageName': ]
create_model_response = sm.create_model(
ModelName = model_name,
ExecutionRoleArn = role,
Containers = container_list
)
Ensuite, je crée le point de terminaison d’inférence sans serveur. N’oubliez pas que vous pouvez créer, mettre à jour, décrire et supprimer un point de terminaison d’inférence sans serveur à l’aide de la console SageMaker, des kits SDK AWS, du kit SDK Python SageMaker, de l’AWS CLI ou d’AWS CloudFormation. Par souci de cohérence, je continue à utiliser Boto3 dans ce deuxième exemple.
Comme dans le premier exemple, je commence par créer la configuration du point de terminaison avec la configuration sans serveur souhaitée. Je spécifie la taille de la mémoire de 5120 Mo et un nombre maximum de cinq appels simultanés pour mon point de terminaison.
endpoint_config_name="roberta-womens-clothing-serverless-ep-config"
create_endpoint_config_response = sm.create_endpoint_config(
EndpointConfigName = endpoint_config_name,
ProductionVariants=[
'ServerlessConfig':
'MemorySizeInMB' : 5120,
'MaxConcurrency' : 5
,
'ModelName':model_name,
'VariantName':'AllTraffic'])
Ensuite, je crée le point de terminaison SageMaker Serverless Inference en appelant le create_endpoint() méthode.
endpoint_name="roberta-womens-clothing-serverless-2"
create_endpoint_response = sm.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name)
Une fois que l’état du point de terminaison s’affiche InService, vous pouvez commencer à envoyer des demandes d’inférence. Encore une fois, par souci de cohérence, je choisis d’exécuter l’exemple de prédiction à l’aide de Boto3 et du client d’exécution SageMaker invoke_endpoint() méthode.
sm_runtime = boto3.client("sagemaker-runtime")
response = sm_runtime.invoke_endpoint(
EndpointName=endpoint_name,
ContentType="application/jsonlines",
Accept="application/jsonlines",
Body=bytes('"features": ["I love this product!"]', 'utf-8')
)
print(response['Body'].read().decode('utf-8'))
"probability": 0.966135561466217, "predicted_label": 1
Comment optimiser votre modèle pour l’inférence sans serveur SageMaker
SageMaker Serverless Inference met automatiquement à l’échelle les ressources de calcul sous-jacentes pour traiter les demandes. Si le point de terminaison ne reçoit pas de trafic pendant un certain temps, il réduit les ressources de calcul. Si le point de terminaison reçoit soudainement de nouvelles demandes, vous remarquerez peut-être qu’il faut un certain temps au point de terminaison pour augmenter les ressources de calcul afin de traiter les demandes.
Ce temps de démarrage à froid dépend grandement de la taille de votre modèle et du temps de démarrage de votre conteneur. Pour optimiser les temps de démarrage à froid, vous pouvez essayer de minimiser la taille de votre modèle, par exemple, en appliquant des techniques telles que la distillation des connaissances, la quantification ou l’élagage du modèle.
La distillation des connaissances utilise un modèle plus grand (le modèle de l’enseignant) pour entraîner des modèles plus petits (modèles des étudiants) à résoudre la même tâche. La quantification réduit la précision des nombres représentant les paramètres de votre modèle à partir de nombres à virgule flottante 32 bits jusqu’à des nombres entiers à virgule flottante 16 bits ou 8 bits. L’élagage du modèle supprime les paramètres de modèle redondants qui contribuent peu au processus de formation.
Disponibilité et prix
Amazon SageMaker Serverless Inference est désormais disponible dans toutes les régions AWS où Amazon Sage Maker est disponible sauf pour les régions AWS GovCloud (États-Unis) et AWS Chine.
Avec SageMaker Serverless Inference, vous ne payez que la capacité de calcul utilisée pour traiter les demandes d’inférence, facturée à la milliseconde, et la quantité de données traitées. Les frais de capacité de calcul dépendent également de la configuration de mémoire que vous choisissez. Pour des informations détaillées sur les prix, visitez la page de tarification de SageMaker.
Commencez dès aujourd’hui avec l’inférence sans serveur Amazon SageMaker
Pour en savoir plus sur l’inférence sans serveur Amazon SageMaker, visitez le Amazon Sage Maker page web d’inférence d’apprentissage automatique. Voici des exemples de blocs-notes SageMaker Serverless Inference qui vous aideront à démarrer immédiatement. Essayez-les depuis la console SageMaker et dites-nous ce que vous en pensez.