Vient maintenant la partie la plus difficile, AMD : Logiciel

Dès le moment où les premières rumeurs ont circulé selon lesquelles AMD envisageait d’acquérir le fabricant de FPGA Xilinx, nous pensions que cet accord concernait autant le logiciel que le matériel.
Nous aimons cet étrange état quantique entre le matériel et le logiciel où les portes programmables dans les FPGA, mais ce n’était pas aussi important. L’accès à tout un ensemble de nouveaux clients intégrés était également très important. Mais l’accord avec Xilinx concernait vraiment le logiciel et les compétences que Xilinx a accumulées au fil des décennies en créant des flux de données et des algorithmes très précis pour résoudre des problèmes où la latence et la localité comptent.
Après les présentations de la journée des analystes financiers le mois dernier, nous avons réfléchi à celle de Victor Peng, ancien directeur général de Xilinx et maintenant président du groupe d’informatique adaptative et embarquée d’AMD.
Ce groupe mélange les CPU et GPU embarqués d’AMD avec les FPGA Xilinx et compte plus de 6 000 clients. Il a rapporté un total de 3,2 milliards de dollars en 2021 et est sur le point de croître d’environ 22 % cette année pour atteindre environ 3,9 milliards de dollars ; Surtout, Xilinx avait un marché adressable total d’environ 33 milliards de dollars pour 2025, mais avec la combinaison d’AMD et de Xilinx, le TAM est passé à 105 milliards de dollars pour l’AECG. Sur ce montant, 13 milliards de dollars proviennent du marché des centres de données auquel Xilinx tente de répondre, 33 milliards de dollars proviennent de systèmes embarqués de toutes sortes (usines, armes, etc.), 27 milliards de dollars proviennent du secteur automobile (Lidar, Radar, caméras , parking automatisé, la liste est longue), et 32 milliards de dollars proviennent du secteur des communications (les stations de base 5G étant la charge de travail importante). Soit dit en passant, cela représente environ un tiers des 304 milliards de dollars TAM pour 2025 du nouvel AMD amélioré. (Vous pouvez voir comment ce TAM a explosé au cours des cinq dernières années ici. C’est remarquable, et c’est pourquoi nous l’avons remarqué en détail.)
Mais un TAM n’est pas une source de revenus, juste un glacier géant au loin qui peut être fondu avec brio pour en faire un.
Au cœur de la stratégie se trouve la poursuite par AMD de ce que Peng a appelé l’IA omniprésente, ce qui signifie l’utilisation d’un mélange de CPU, de GPU et de FPGA pour répondre à ce marché en pleine explosion. Cela signifie également tirer parti du travail effectué par AMD pour concevoir des systèmes exascale en collaboration avec Hewlett Packard Enterprise et certains des principaux centres HPC du monde pour continuer à étoffer une pile HPC. AMD aura besoin des deux s’il espère concurrencer Nvidia et tenir Intel à distance. CUDA est une plate-forme formidable, et oneAPI pourrait l’être si Intel s’y tient.
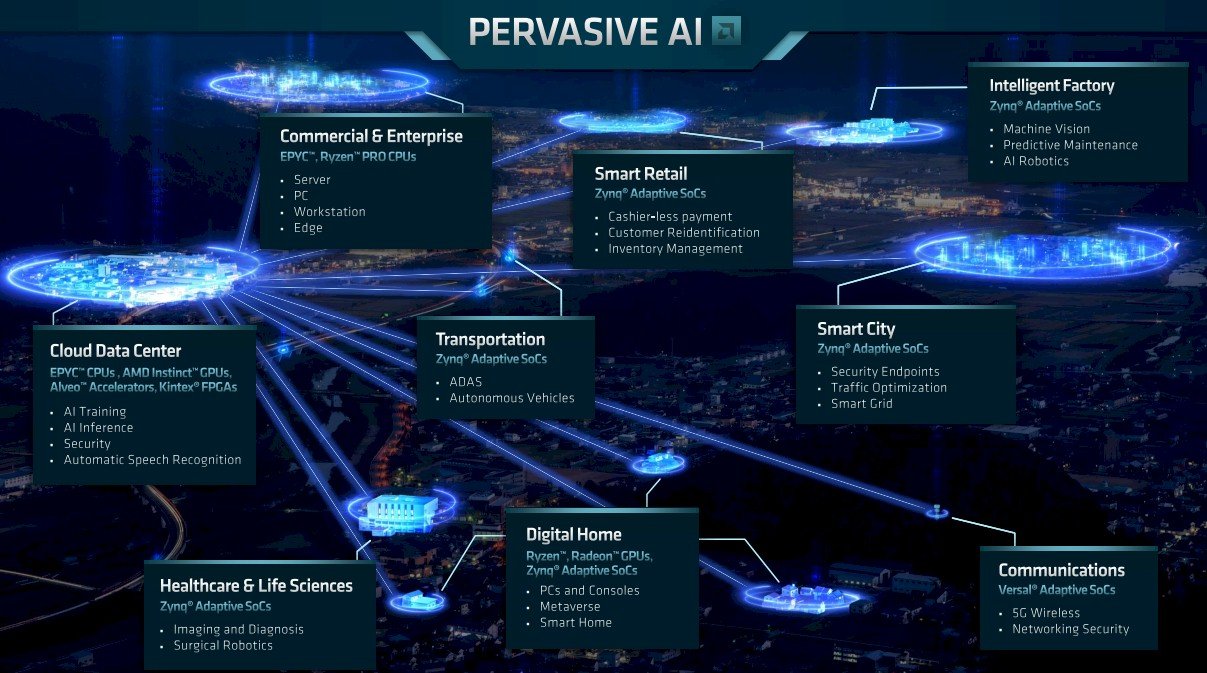
Quand j’étais chez Xilinx, je n’ai jamais dit que l’informatique adaptative était la fin de l’informatique, a expliqué Peng dans son discours d’ouverture. Un processeur va toujours entraîner une grande partie des charges de travail, tout comme les GPU. Mais j’ai toujours dit que dans un monde en changement, l’adaptabilité est vraiment un attribut incroyablement précieux. Le changement se produit partout où vous en entendez parler, l’architecture d’un datacenter change. La plate-forme des voitures change totalement. L’industriel change. Il y a du changement partout. Et si le matériel est adaptable, cela signifie non seulement que vous pouvez le changer après sa fabrication, mais que vous pouvez le changer même lorsqu’il est déployé sur le terrain.
Eh bien, on peut en dire autant des logiciels, qui suivent bien sûr le matériel. Même si Peng n’a pas dit cela. Les gens s’amusaient avec SmallTalk à la fin des années 1980 et au début des années 1990 après avoir mûri pendant deux décennies en raison de la nature orientée objet de la programmation, mais le marché a choisi ce que nous dirions être un Java inférieur quelques années plus tard parce que de sa portabilité absolue grâce à la Java Virtual Machine. Les entreprises veulent non seulement avoir les options de nombreux matériels différents, spécialement adaptés aux situations et aux charges de travail, mais elles veulent également que le code soit portable dans ces scénarios.
C’est pourquoi Nvidia a besoin d’un processeur capable d’exécuter CUDA (nous savons à quel point cela semble bizarre), et pourquoi Intel crée une API et oint Data Parallel C++ avec SYCL comme son espéranto sur les processeurs, les GPU, les FPGA, les NNP et tout ce qui vient d’autre. avec.
C’est aussi pourquoi AMD avait besoin de Xilinx. AMD a bien beaucoup d’ingénieurs, au nord de 16 000 d’entre eux maintenant et beaucoup d’entre eux écrivent des logiciels. Mais comme nous l’expliquait en novembre dernier Jensen Huang, co-fondateur et PDG de Nvidia, les trois quarts des 22 500 employés de Nvidia sont logiciel d’écriture. Et cela se voit dans l’étendue et la profondeur des outils de développement, des algorithmes, des cadres, des intergiciels disponibles pour CUDA et comment cette variante de l’accélération GPU est devenue la de facto standard pour des milliers d’applications. Si AMD devait disposer de l’expertise algorithmique et industrielle pour porter des applications sur une pile combinée ROCm et Vitis, et le faire en moins de temps que Nvidia n’en a pris, il fallait acheter cette expertise industrielle.
C’est pourquoi Xilinx a coûté 49 milliards de dollars à AMD. Et c’est aussi pourquoi AMD va devoir investir beaucoup plus dans les développeurs de logiciels que par le passé, et pourquoi l’interface hétérogène pour la portabilité, ou HIP, API, qui est une API de type CUDA qui permet aux temps d’exécution de cibler une variété de processeurs ainsi que les GPU Nvidia et AMD, est un élément clé de ROCm. Cela permet à AMD de prendre beaucoup plus rapidement en charge les applications CUDA pour son matériel GPU.
Mais à long terme, AMD doit disposer de sa propre pile complète couvrant tous les cas d’utilisation de l’IA sur ses nombreux appareils :
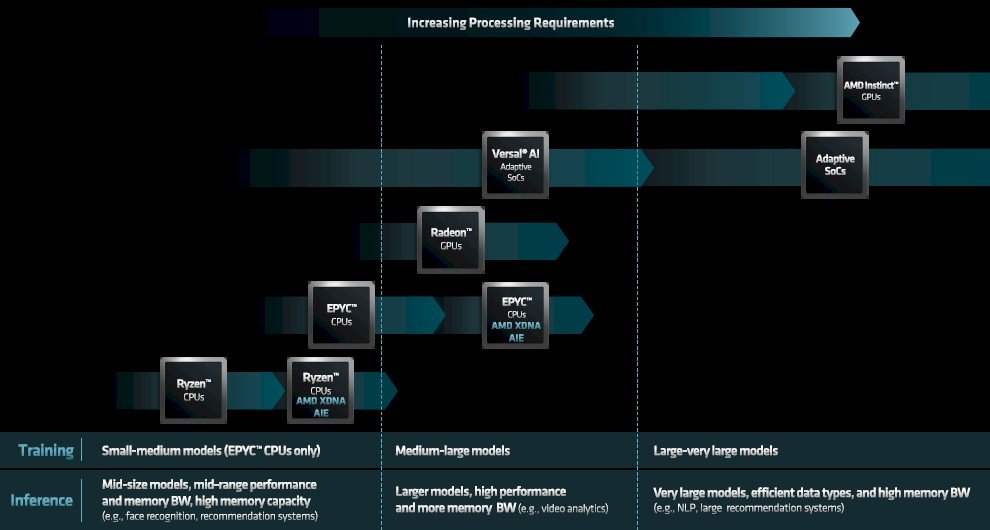
Cette pile a évolué, et Peng la dirigera à partir de maintenant avec l’aide de certains de ces centres HPC qui ont exploité les processeurs et les GPU AMD comme moteurs de calcul dans les supercalculateurs de classe pré-exascale et exascale.
Peng n’a pas du tout parlé de simulation et de modélisation HPC dans sa présentation et n’a que légèrement évoqué l’idée qu’AMD créerait une pile de formation IA au-dessus du logiciel ROCm créé pour HPC. Ce qui est logique. Mais il a montré comment la pile d’inférence IA chez AMD évoluerait, et avec cela, nous pouvons établir des parallèles entre le HPC, la formation IA et l’inférence IA.
Voici à quoi ressemble aujourd’hui la pile logicielle d’inférence IA pour les CPU, les GPU et les FPGA chez AMD :

Avec la première itération de son logiciel d’inférence d’IA unifié que Peng a appelé Unified AI Stack 1.0, les équipes logicielles d’AMD et de l’ancien Xilinx vont créer un frontal d’inférence unifié qui peut couvrir les compilateurs de graphes ML sur les trois ensembles différents de calcul ainsi que les frameworks d’IA populaires, puis compilez le code vers ces appareils individuellement.

Mais à long terme, avec Unified AI Stack 2.0, les compilateurs de graphes ML sont unifiés et un ensemble commun de bibliothèques couvre tous ces appareils ; de plus, certains des blocs AI Engine DSP qui sont codés en dur dans les FPGA Versal seront déplacés vers les processeurs et les compilateurs Zen Studio AOCC et Vitis AI Engine seront mélangés pour créer des runtimes pour les systèmes d’exploitation Windows et Linux pour les APU qui ajoutent l’IA Moteurs d’inférence pour les processeurs Epyc et Ryzen.
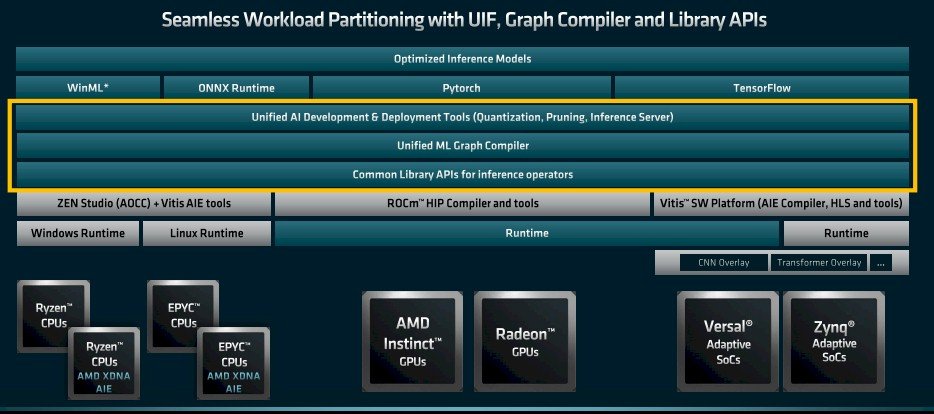
Et cela, en termes de logiciel, est la partie la plus facile. Après avoir créé une pile d’inférence d’IA unifiée, AMD doit créer une pile de formation HPC et IA unifiée au sommet de ROCm, ce qui n’est pas si grave, puis le travail acharné commence. Cela permet d’obtenir les près de 1 000 éléments clés d’applications open source et fermées qui s’exécutent sur des processeurs et des GPU portés afin qu’ils puissent fonctionner sur n’importe quelle combinaison de matériel qu’AMD peut apporter et probablement aussi sur le matériel de ses concurrents.
C’est le seul moyen de battre Nvidia et de déséquilibrer Intel.