
Utilisez des modèles de base d’IA génératifs en mode VPC sans connectivité Internet à l’aide d’Amazon SageMaker JumpStart | Services Web Amazon
Avec les progrès récents de l’IA générative, de nombreuses discussions ont lieu sur la manière d’utiliser l’IA générative dans différents secteurs pour résoudre des problèmes commerciaux spécifiques. L’IA générative est un type d’IA capable de créer de nouveaux contenus et de nouvelles idées, notamment des conversations, des histoires, des images, des vidéos et de la musique. Tout cela s’appuie sur de très grands modèles pré-entraînés sur de grandes quantités de données et communément appelés modèles de base (FM). Ces FM peuvent effectuer un large éventail de tâches couvrant plusieurs domaines, comme rédiger des articles de blog, générer des images, résoudre des problèmes mathématiques, engager un dialogue et répondre à des questions basées sur un document. La taille et la nature générale des FM les différencient des modèles ML traditionnels, qui effectuent généralement des tâches spécifiques, telles que l’analyse du texte à la recherche de sentiments, la classification d’images et la prévision des tendances.
Alors que les organisations cherchent à utiliser la puissance de ces FM, elles souhaitent également que les solutions basées sur FM s’exécutent dans leurs propres environnements protégés. Les organisations opérant dans des espaces fortement réglementés tels que les services financiers mondiaux, la santé et les sciences de la vie ont des exigences d’audit et de conformité pour gérer leur environnement dans leurs VPC. En fait, bien souvent, même l’accès direct à Internet est désactivé dans ces environnements pour éviter toute exposition à tout trafic involontaire, tant en entrée qu’en sortie.
Amazon SageMaker JumpStart est un hub ML proposant des algorithmes, des modèles et des solutions ML. Avec SageMaker JumpStart, les praticiens du ML peuvent choisir parmi une liste croissante de FM open source les plus performants. Il offre également la possibilité de déployer ces modèles dans votre propre Virtual Private Cloud (VPC).
Dans cet article, nous montrons comment utiliser JumpStart pour déployer un modèle Flan-T5 XXL dans un VPC sans connectivité Internet. Nous abordons les sujets suivants :
- Comment déployer un modèle de base à l’aide de SageMaker JumpStart dans un VPC sans accès Internet
- Avantages du déploiement de FM via les modèles SageMaker JumpStart en mode VPC
- Autres moyens de personnaliser le déploiement des modèles de base via JumpStart
Outre le FLAN-T5 XXL, JumpStart propose de nombreux modèles de fondations différents pour diverses tâches. Pour obtenir la liste complète, consultez Mise en route avec Amazon SageMaker JumpStart.
Vue d’ensemble de la solution
Dans le cadre de la solution, nous couvrons les étapes suivantes :
- Configurez un VPC sans connexion Internet.
- Configurez Amazon SageMaker Studio à l’aide du VPC que nous avons créé.
- Déployez le modèle de base génératif AI Flan T5-XXL à l’aide de JumpStart dans le VPC sans accès à Internet.
Ce qui suit est un schéma d’architecture de la solution.
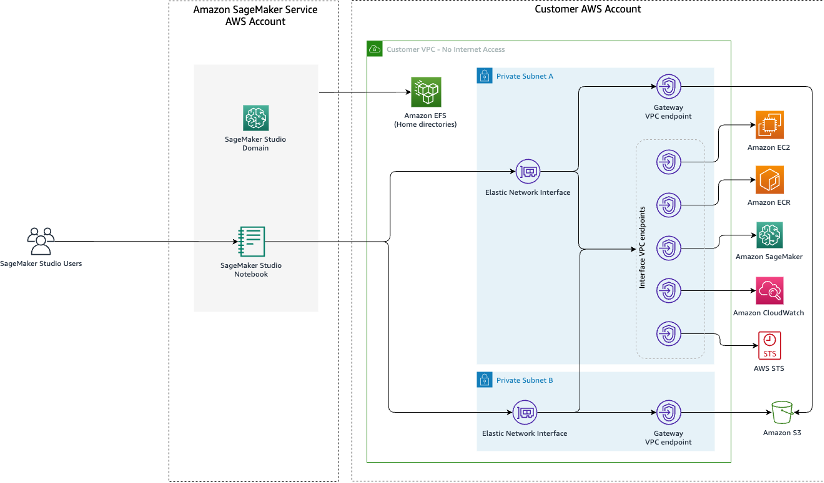
Passons en revue les différentes étapes pour mettre en œuvre cette solution.
Conditions préalables
Pour suivre cet article, vous avez besoin des éléments suivants :
Configurer un VPC sans connexion Internet
Créez une nouvelle pile CloudFormation à l’aide du modèle 01_networking.yaml. Ce modèle crée un nouveau VPC et ajoute deux sous-réseaux privés sur deux zones de disponibilité sans connectivité Internet. Il déploie ensuite les points de terminaison d’un VPC de passerelle pour accéder à Amazon Simple Storage Service (Amazon S3) et interface les points de terminaison du VPC pour SageMaker et quelques autres services afin de permettre aux ressources du VPC de se connecter aux services AWS via AWS PrivateLink.
Fournissez un nom de pile, tel que No-Internetet terminez le processus de création de la pile.
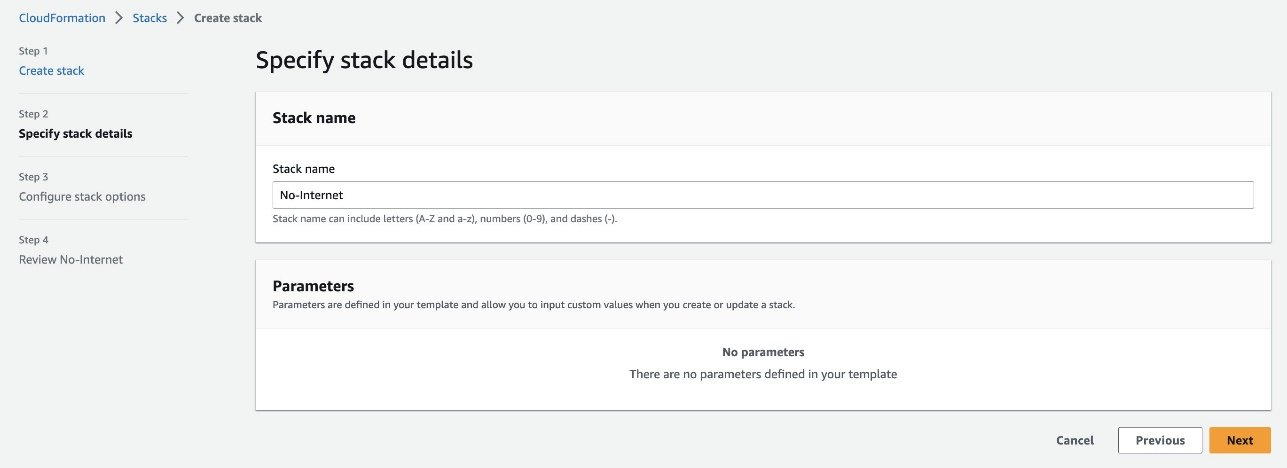
Cette solution n’est pas hautement disponible, car le modèle CloudFormation crée des points de terminaison de VPC d’interface uniquement dans un sous-réseau pour réduire les coûts lorsque vous suivez les étapes de cet article.
Configurer Studio à l’aide du VPC
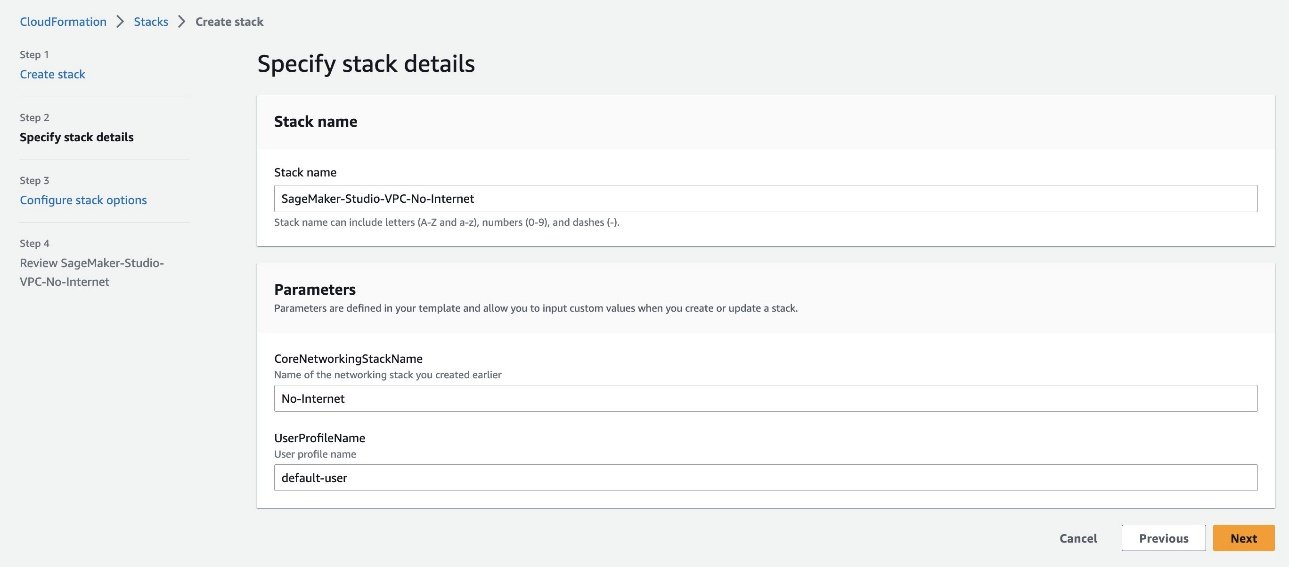
Créez une autre pile CloudFormation à l’aide de 02_sagemaker_studio.yaml, qui crée un domaine Studio, un profil utilisateur Studio et des ressources de prise en charge telles que les rôles IAM. Choisissez un nom pour la pile ; pour cet article, nous utilisons le nom SageMaker-Studio-VPC-No-Internet. Fournissez le nom de la pile VPC que vous avez créée précédemment (No-Internet) comme le CoreNetworkingStackName paramètre et laissez tout le reste par défaut.
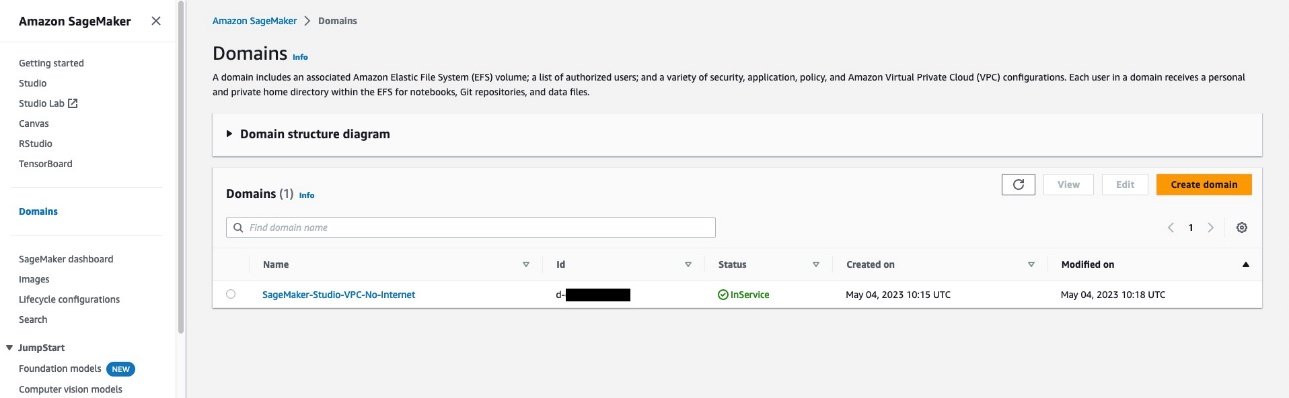
Attendez qu’AWS CloudFormation signale que la création de la pile est terminée. Vous pouvez confirmer que le domaine Studio est disponible sur la console SageMaker.
Pour vérifier que l’utilisateur du domaine Studio n’a pas accès à Internet, lancez Studio à l’aide de la console SageMaker. Choisir Déposer, Nouveauet Terminal, puis essayez d’accéder à une ressource Internet. Comme le montre la capture d’écran suivante, le terminal continuera d’attendre la ressource et finira par expirer.
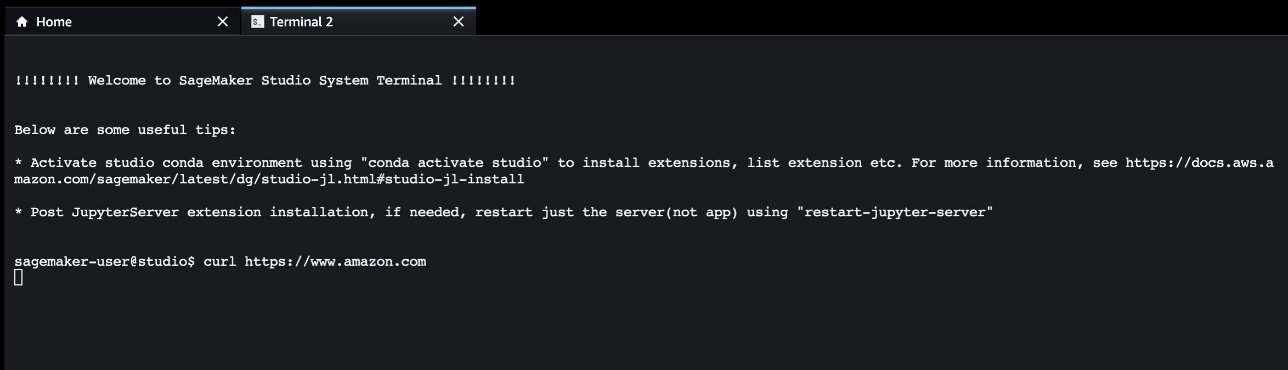
Cela prouve que Studio fonctionne dans un VPC qui n’a pas accès à Internet.
Déployez le modèle de base d’IA générative Flan T5-XXL à l’aide de JumpStart
Nous pouvons déployer ce modèle via Studio ainsi que via API. JumpStart fournit tout le code pour déployer le modèle via un notebook SageMaker accessible depuis Studio. Pour cet article, nous présentons cette fonctionnalité du Studio.
- Sur la page d’accueil de Studio, choisissez Début de saut sous Solutions prédéfinies et automatisées.
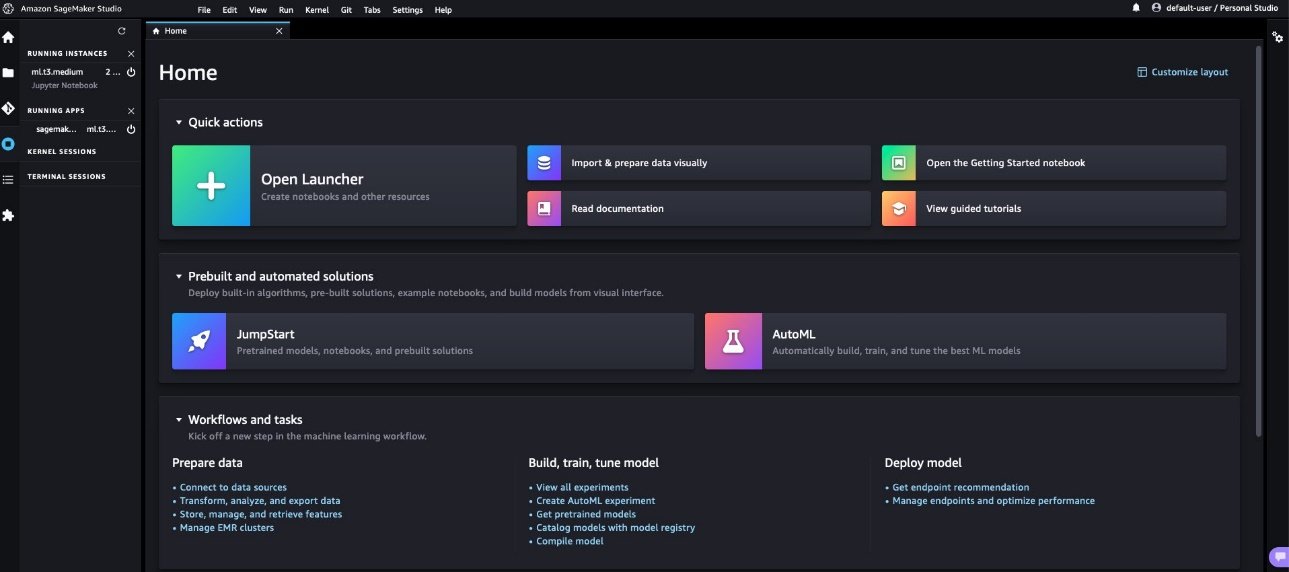
- Choisissez le modèle Flan-T5 XXL ci-dessous Modèles de fondation.
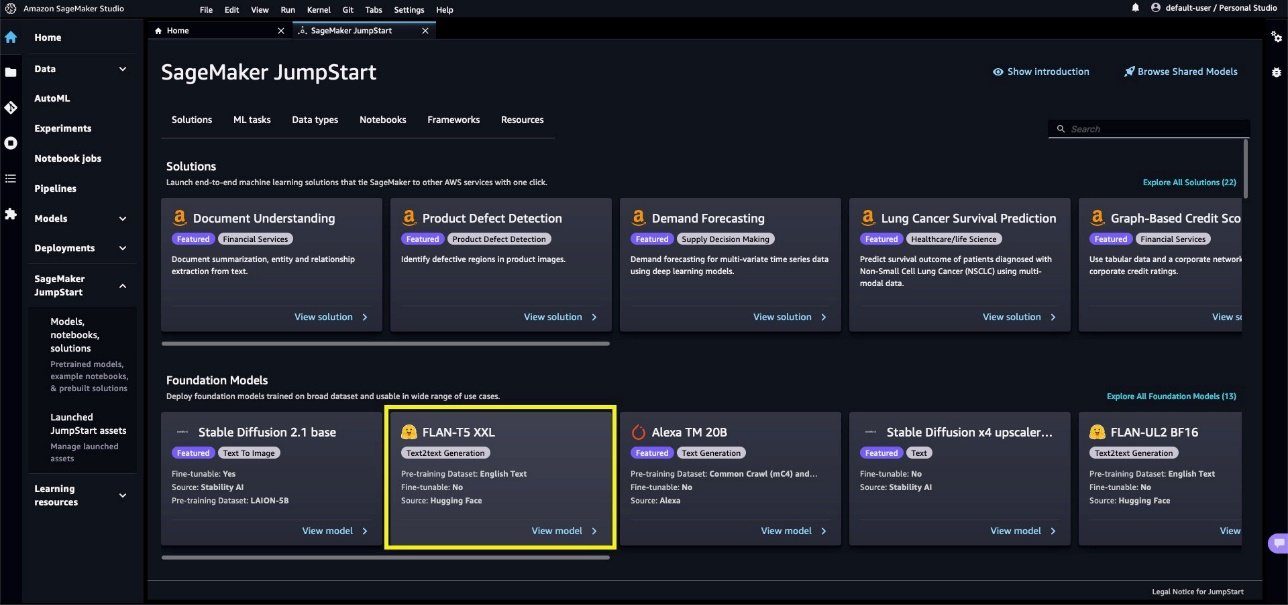
- Par défaut, il ouvre le Déployer languette. Élargir la Configuration du déploiement section pour modifier le
hosting instanceetendpoint name, ou ajoutez des balises supplémentaires. Il existe également une option pour modifier leS3 bucket locationoù l’artefact du modèle sera stocké pour créer le point de terminaison. Pour cet article, nous laissons tout à ses valeurs par défaut. Notez le nom du point de terminaison à utiliser lors de l’appel du point de terminaison pour effectuer des prédictions.
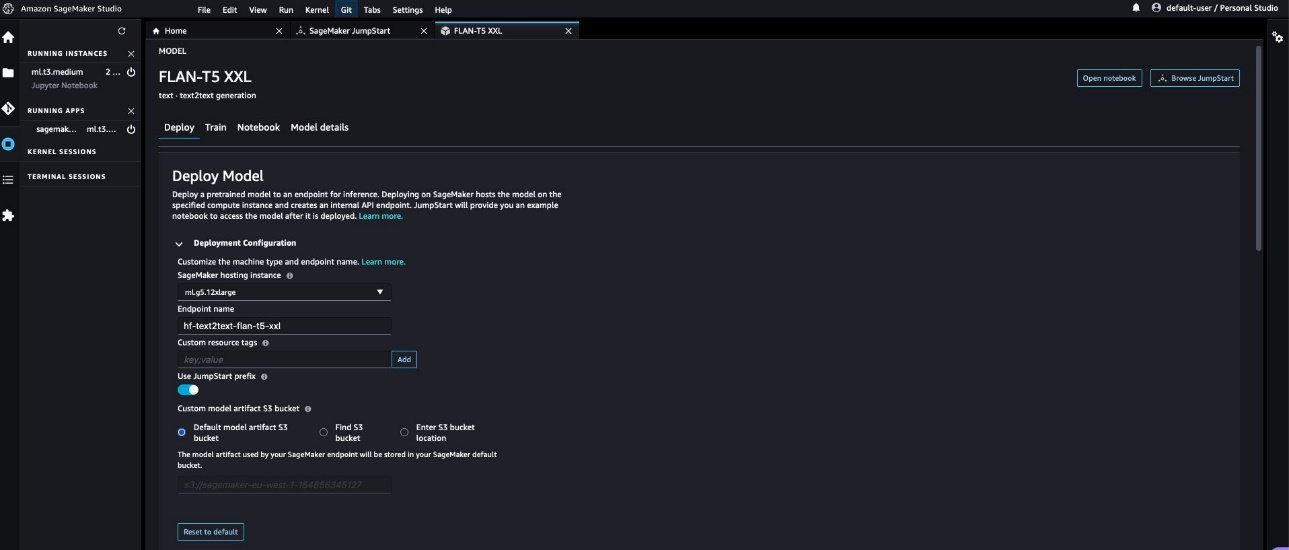
- Élargir la Les paramètres de sécurité section, où vous pouvez spécifier le
IAM rolepour créer le point de terminaison. Vous pouvez également spécifier leVPC configurationsen fournissant lesubnetsetsecurity groups. Les ID de sous-réseau et les ID de groupe de sécurité peuvent être trouvés dans l’onglet Sorties des piles VPC sur la console AWS CloudFormation. SageMaker JumpStart nécessite au moins deux sous-réseaux dans le cadre de cette configuration. Les sous-réseaux et les groupes de sécurité contrôlent l’accès vers et depuis le conteneur de modèles.
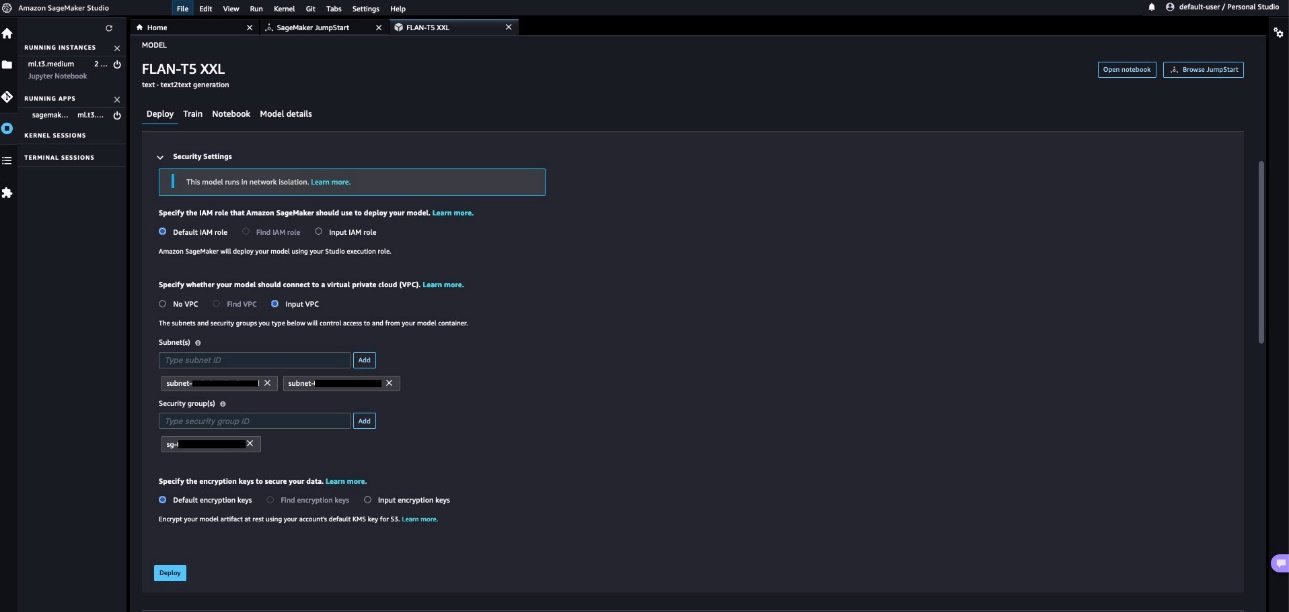
NOTE: Que le modèle SageMaker JumpStart soit déployé ou non dans le VPC, le modèle s’exécute toujours en mode d’isolation réseau, ce qui isole le conteneur de modèle afin qu’aucun appel réseau entrant ou sortant ne puisse être effectué vers ou depuis le conteneur de modèle. Parce que nous utilisons un VPC, SageMaker télécharge l’artefact de modèle via notre VPC spécifié. L’exécution du conteneur de modèles en isolation réseau n’empêche pas votre point de terminaison SageMaker de répondre aux demandes d’inférence. Un processus serveur s’exécute parallèlement au conteneur de modèle et lui transmet les demandes d’inférence, mais le conteneur de modèle n’a pas d’accès au réseau.
- Choisir Déployer pour déployer le modèle. Nous pouvons voir l’état en temps quasi réel de la création du point de terminaison en cours. La création du point de terminaison peut prendre 510 minutes.
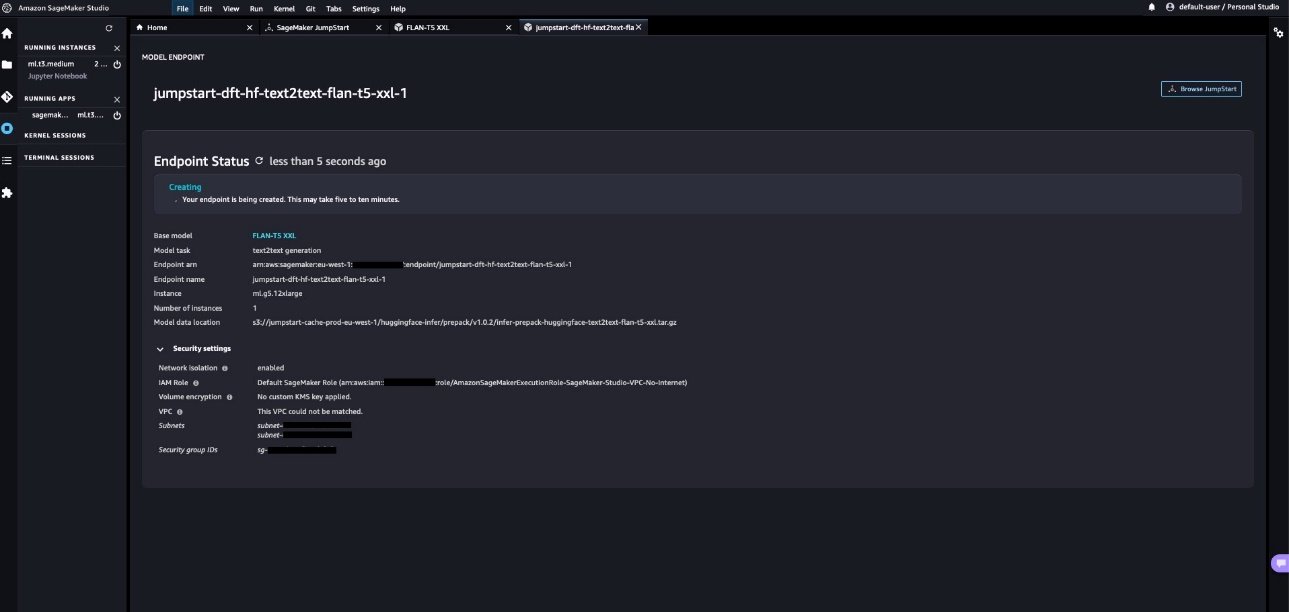
Observez la valeur du champ Emplacement des données du modèle sur cette page. Tous les modèles SageMaker JumpStart sont hébergés sur un compartiment S3 géré par SageMaker (s3://jumpstart-cache-prod-{region}). Par conséquent, quel que soit le modèle sélectionné dans JumpStart, le modèle est déployé à partir du compartiment SageMaker JumpStart S3 accessible au public et le trafic n’est jamais dirigé vers les API publiques du zoo de modèles pour télécharger le modèle. C’est pourquoi la création du point de terminaison du modèle a démarré avec succès même lors de la création du point de terminaison dans un VPC qui n’a pas d’accès direct à Internet.
L’artefact du modèle peut également être copié dans n’importe quel zoo de modèles privé ou dans votre propre compartiment S3 pour contrôler et sécuriser davantage l’emplacement de la source du modèle. Vous pouvez utiliser la commande suivante pour télécharger le modèle localement à l’aide de l’AWS Command Line Interface (AWS CLI) :
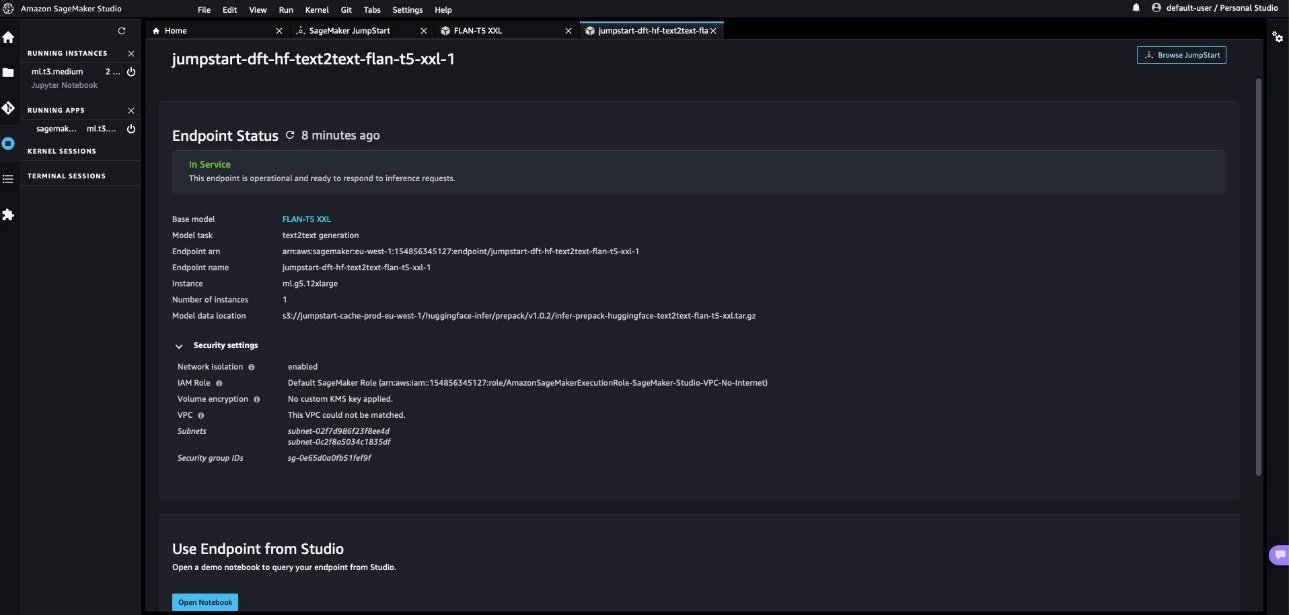
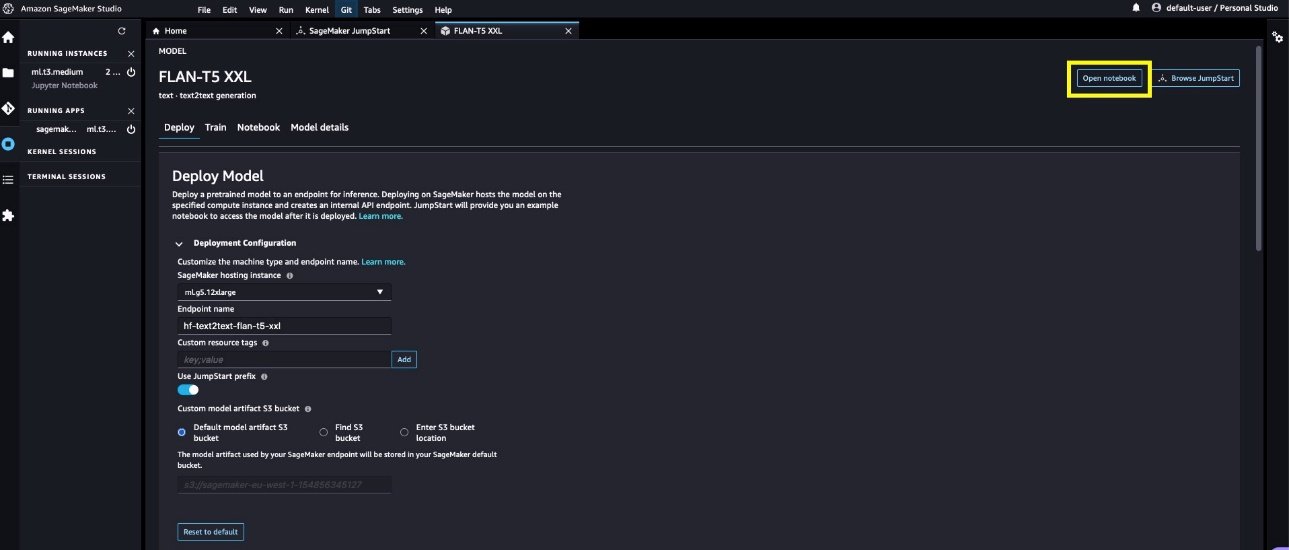
aws s3 cp s3://jumpstart-cache-prod-eu-west-1/huggingface-infer/prepack/v1.0.2/infer-prepack-huggingface-text2text-flan-t5-xxl.tar.gz .- Après quelques minutes, le point de terminaison est créé avec succès et affiche l’état comme suit : En service. Choisir
Open Notebookdans leUse Endpoint from Studiosection. Il s’agit d’un exemple de bloc-notes fourni dans le cadre de l’expérience JumpStart pour tester rapidement le point de terminaison.
- Dans le cahier, choisissez l’image comme Science des données 3.0 et le noyau comme Python3. Lorsque le noyau est prêt, vous pouvez exécuter les cellules du notebook pour effectuer des prédictions sur le point de terminaison. Notez que le bloc-notes utilise l’API Ensure_endpoint() du kit AWS SDK pour Python pour effectuer des prédictions. Vous pouvez également utiliser la méthode Predict() des SDK Python de SageMaker pour obtenir le même résultat.
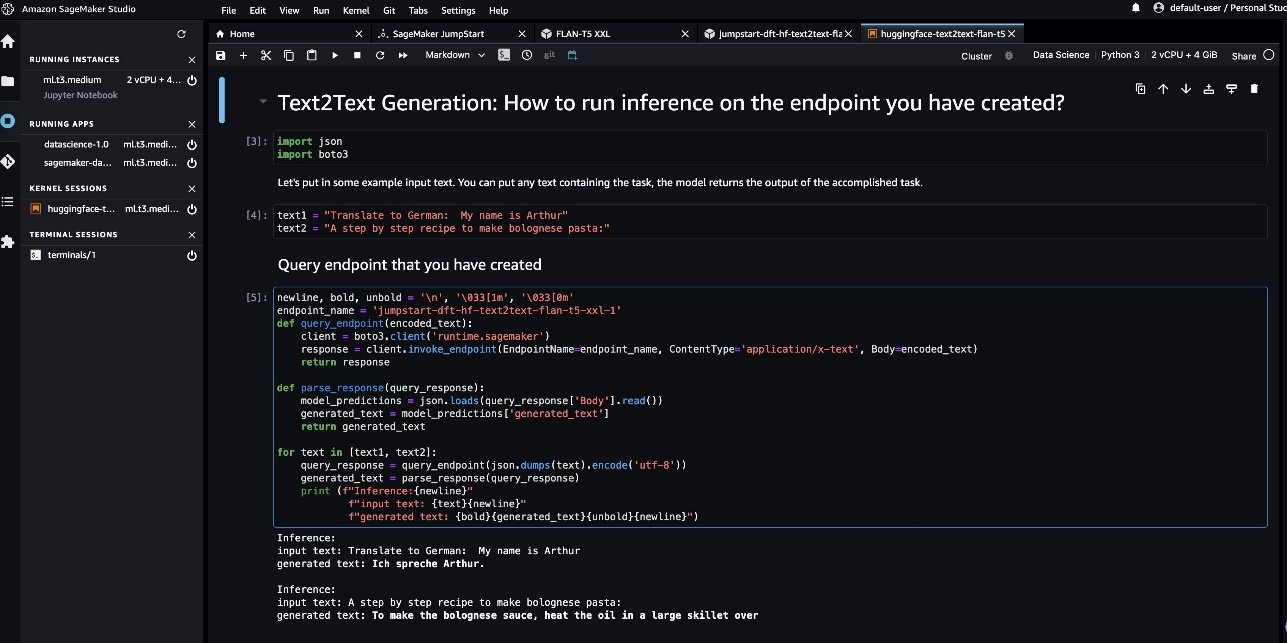
Ceci conclut les étapes de déploiement du modèle Flan-T5 XXL à l’aide de JumpStart dans un VPC sans accès Internet.
Avantages du déploiement de modèles SageMaker JumpStart en mode VPC
Voici quelques-uns des avantages du déploiement de modèles SageMaker JumpStart en mode VPC :
- Étant donné que SageMaker JumpStart ne télécharge pas les modèles à partir d’un zoo de modèles public, il peut également être utilisé dans des environnements entièrement verrouillés où il n’y a pas d’accès Internet.
- Étant donné que l’accès au réseau peut être limité et limité aux modèles SageMaker JumpStart, cela aide les équipes à améliorer la sécurité de l’environnement.
- En raison des limites du VPC, l’accès au point de terminaison peut également être limité via des sous-réseaux et des groupes de sécurité, ce qui ajoute une couche de sécurité supplémentaire.
Autres moyens de personnaliser le déploiement des modèles de base via SageMaker JumpStart
Dans cette section, nous partageons quelques autres façons de déployer le modèle.
Utilisez les API SageMaker JumpStart de votre IDE préféré
Les modèles fournis par SageMaker JumpStart ne nécessitent pas que vous accédiez à Studio. Vous pouvez les déployer sur les points de terminaison SageMaker à partir de n’importe quel IDE, grâce aux API JumpStart. Vous pouvez ignorer l’étape de configuration de Studio évoquée plus haut dans cet article et utiliser les API JumpStart pour déployer le modèle. Ces API fournissent des arguments dans lesquels les configurations VPC peuvent également être fournies. Les API font partie du SDK SageMaker Python lui-même. Pour plus d’informations, reportez-vous à Modèles pré-entraînés.
Utilisez les blocs-notes fournis par SageMaker JumpStart de SageMaker Studio
SageMaker JumpStart fournit également des notebooks pour déployer le modèle directement. Sur la page de détails du modèle, choisissez Cahier ouvert pour ouvrir un exemple de bloc-notes contenant le code permettant de déployer le point de terminaison. Le notebook utilise les API SageMaker JumpStart Industry qui vous permettent de répertorier et de filtrer les modèles, de récupérer les artefacts, ainsi que de déployer et d’interroger les points de terminaison. Vous pouvez également modifier le code du notebook en fonction des exigences spécifiques à votre cas d’utilisation.
Nettoyer les ressources
Consultez le fichier CLEANUP.md pour trouver les étapes détaillées pour supprimer le Studio, le VPC et d’autres ressources créées dans le cadre de cet article.
Dépannage
Si vous rencontrez des problèmes lors de la création des piles CloudFormation, reportez-vous à Dépannage de CloudFormation.
Conclusion
L’IA générative alimentée par de grands modèles linguistiques change la façon dont les gens acquièrent et appliquent les informations tirées des informations. Cependant, les organisations opérant dans des espaces fortement réglementés doivent utiliser les capacités de l’IA générative d’une manière qui leur permet d’innover plus rapidement, mais qui simplifie également les modèles d’accès à ces capacités.
Nous vous encourageons à essayer l’approche proposée dans cet article pour intégrer des fonctionnalités d’IA générative dans votre environnement existant tout en les conservant dans votre propre VPC sans accès à Internet. Pour en savoir plus sur les modèles de base SageMaker JumpStart, consultez les éléments suivants :
À propos des auteurs
 Vikesh Pandey est un architecte de solutions spécialisé en apprentissage automatique chez AWS, aidant les clients des secteurs financiers à concevoir et à créer des solutions sur l’IA générative et le ML. En dehors du travail, Vikesh aime essayer différentes cuisines et pratiquer des sports de plein air.
Vikesh Pandey est un architecte de solutions spécialisé en apprentissage automatique chez AWS, aidant les clients des secteurs financiers à concevoir et à créer des solutions sur l’IA générative et le ML. En dehors du travail, Vikesh aime essayer différentes cuisines et pratiquer des sports de plein air.
 Mehran Nikoo est architecte de solutions senior chez AWS, travaillant avec des entreprises Digital Native au Royaume-Uni et les aidant à atteindre leurs objectifs. Passionné par l’application de son expérience en génie logiciel à l’apprentissage automatique, il se spécialise dans les pratiques d’apprentissage automatique de bout en bout et de MLOps.
Mehran Nikoo est architecte de solutions senior chez AWS, travaillant avec des entreprises Digital Native au Royaume-Uni et les aidant à atteindre leurs objectifs. Passionné par l’application de son expérience en génie logiciel à l’apprentissage automatique, il se spécialise dans les pratiques d’apprentissage automatique de bout en bout et de MLOps.