L’informatique neuromorphique aura besoin de partenaires pour s’introduire dans le centre de données

Le domaine émergent du traitement neuromorphique n’est pas facile à naviguer. Il existe des acteurs majeurs dans le domaine qui tirent parti de leur taille et de leurs vastes ressources, le profil le plus élevé étant Intel avec ses processeurs Loihi et l’initiative TrueNorth d’IBM et une liste croissante de startups telles que SynSense, Innatera Nanosystems et GrAI Matter Labs.
Inclus dans cette dernière liste est BrainChip, une société qui développe sa puce Akida Akida est grec pour le pic et la propriété intellectuelle qui l’accompagne depuis plus d’une décennie. Nous avons suivi BrainChip au cours des dernières années, en discutant avec eux en 2018, puis à nouveau deux ans plus tard, et l’entreprise s’est avérée adaptable dans un espace en évolution rapide. Le plan initial était de mettre le SoC commercial sur le marché d’ici 2019, mais BrainChip a prolongé le délai pour ajouter la capacité d’exécuter des réseaux de neurones convolutionnels (CNN) ainsi que des réseaux de neurones à pointes (SNN).
En janvier, la société a annoncé la commercialisation complète de sa plate-forme AKD1000, qui comprend sa carte Mini PCIe qui exploite le processeur de réseau neuronal Akida. C’est un élément clé de la stratégie de BrainChips consistant à utiliser la technologie comme modèles de référence alors qu’elle poursuit des partenariats avec des fournisseurs de matériel et de puces qui l’intégreront dans leurs propres conceptions.
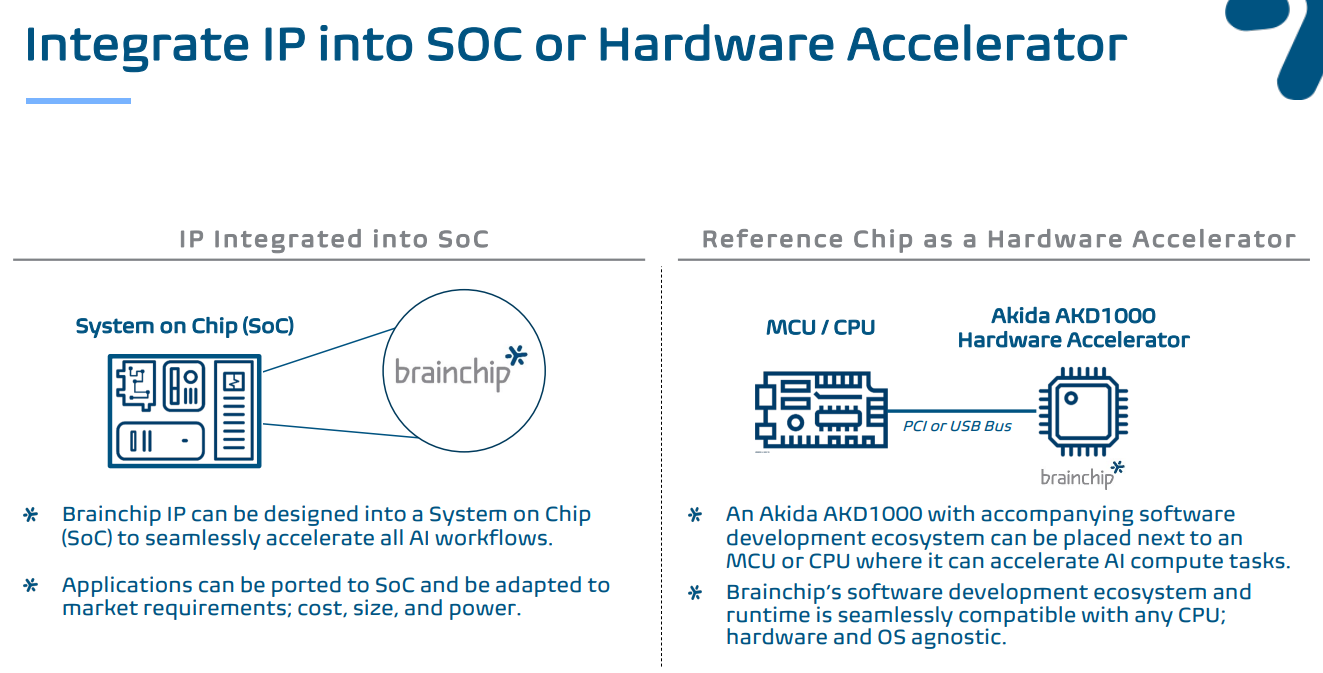 En ce qui concerne notre modèle économique fondamental, s’agit-il d’une puce ou d’une adresse IP, ou des deux ? Jérôme Nadel, directeur marketing de BrainChips, raconte La prochaine plateforme. C’est un modèle de licence IP. Nous avons des puces de référence, mais notre mise sur le marché consiste définitivement à travailler avec des partenaires de l’écosystème, en particulier ceux qui prendraient une licence, comme un fournisseur de puces ou un concepteur d’ASIC et des équipementiers de niveau 1. Si nous sommes connectés avec une conception de référence à des capteurs pour diverses modalités de capteurs ou à un développement de logiciel d’application, lorsque quelqu’un met en place l’activation de l’IA, il veut l’exécuter sur notre matériel et il y a déjà une interopérabilité. Vous verrez beaucoup de ces blocs de construction alors que nous essayons de pénétrer l’écosystème, car en fin de compte, lorsque vous regardez la croissance catégorique de l’IA de pointe, cela va vraiment provenir d’appareils de base qui exploitent des capteurs intelligents.
En ce qui concerne notre modèle économique fondamental, s’agit-il d’une puce ou d’une adresse IP, ou des deux ? Jérôme Nadel, directeur marketing de BrainChips, raconte La prochaine plateforme. C’est un modèle de licence IP. Nous avons des puces de référence, mais notre mise sur le marché consiste définitivement à travailler avec des partenaires de l’écosystème, en particulier ceux qui prendraient une licence, comme un fournisseur de puces ou un concepteur d’ASIC et des équipementiers de niveau 1. Si nous sommes connectés avec une conception de référence à des capteurs pour diverses modalités de capteurs ou à un développement de logiciel d’application, lorsque quelqu’un met en place l’activation de l’IA, il veut l’exécuter sur notre matériel et il y a déjà une interopérabilité. Vous verrez beaucoup de ces blocs de construction alors que nous essayons de pénétrer l’écosystème, car en fin de compte, lorsque vous regardez la croissance catégorique de l’IA de pointe, cela va vraiment provenir d’appareils de base qui exploitent des capteurs intelligents.
BrainChip vise sa technologie à la pointe, où davantage de données devraient être générées dans les années à venir. S’appuyant sur les recherches d’IDC et de McKinsey, BrainChip s’attend à ce que le marché des appareils basés sur la périphérie nécessitant une IA passe de 44 milliards de dollars cette année à 70 milliards de dollars d’ici 2025. En outre, lors de l’événement Dell Technologies World de la semaine dernière, le PDG Michael Dell a réitéré sa conviction 10 % des données sont désormais générées à la périphérie, ce qui passera à 75 % d’ici 2025. Là où les données sont créées, l’IA suivra. BrainChip a conçu Akida pour l’environnement de traitement élevé et à faible consommation d’énergie et pour pouvoir exécuter des charges de travail analytiques d’IA, en particulier l’inférence sur la puce, afin de réduire le flux de données vers et depuis le cloud et ainsi réduire la latence dans la génération des résultats.
Les puces neuromorphiques sont conçues pour imiter le cerveau grâce à l’utilisation de SNN. BrainChip élargit les charges de travail qu’Akida pourrait exécuter en étant également capable d’exécuter des CNN, qui sont utiles dans les environnements périphériques pour des tâches telles que la vision intégrée, l’audio intégré, la conduite automatisée pour les dispositifs de télédétection LiDAR et RADAR et l’IoT industriel. L’entreprise considère des secteurs tels que la conduite autonome, la santé intelligente et les villes intelligentes comme des secteurs de croissance.

BrainChip connaît déjà un certain succès. Sa plate-forme Akida 1000 est utilisée dans le concept-car Mercedes-Benz Vision EQXX pour l’IA en cabine, y compris l’authentification du conducteur et de la voix, la détection de mots clés et la compréhension contextuelle.
L’éditeur voit dans les partenariats une avenue pour accroître sa présence dans le domaine des puces neuromorphiques.
Si nous examinons un plan stratégique quinquennal, nos trois années extérieures sont probablement différentes de nos deux années intérieures, dit Nadel. Dans les deux internes, nous allons toujours nous concentrer sur les fournisseurs et les concepteurs de puces et les équipementiers de niveau 1. Mais les trois autres, si vous regardez les catégories, ça va vraiment venir des appareils de base, qu’ils soient embarqués ou en cabine. que ce soit dans l’électronique grand public qui recherchent cette activation de l’IA. Nous devons être dans l’écosystème. Notre IP est de facto et le modèle d’affaires s’articule autour de cela.
La société a annoncé un certain nombre de partenariats, notamment avec nViso, une société d’analyse de l’IA. La collaboration ciblera les applications alimentées par batterie dans les secteurs de la robotique et de l’automobile utilisant les puces Akida pour la technologie nVisos AI pour les robots sociaux et les systèmes de surveillance en cabine. BrainChip travaille également avec SiFive pour intégrer la technologie Akida aux processeurs SiFives RISC-V pour les charges de travail de calcul d’IA de pointe et MosChip, exécutant son adresse IP Akida avec la plate-forme ASIC du fournisseur pour les appareils intelligents de pointe. BrainChip travaille également avec Arm.
Pour accélérer la stratégie, la société a déployé cette semaine son programme d’activation de l’IA pour offrir aux fournisseurs des prototypes fonctionnels de BrainChip IP sur le matériel Akida afin de démontrer les capacités des plates-formes pour exécuter l’inférence de l’IA et l’apprentissage sur puce et dans un appareil. Le fournisseur offre également une assistance pour l’identification des cas d’utilisation pour l’intégration de capteurs et de modèles.

Le programme comprend trois niveaux, les prototypes de base et avancés à la solution de fonctionnement avec le nombre de puces AKD1000 passant à 100, des modèles personnalisés pour certains utilisateurs, 40 à 160 heures avec des experts en apprentissage automatique et deux à dix systèmes de développement. Les prototypes permettront à BrianChip de proposer ses produits commerciaux aux utilisateurs à un moment où d’autres concurrents développent encore leurs propres technologies sur un marché relativement naissant.
Il y a une étape pour être clair sur les cas d’utilisation et peut-être une feuille de route d’intégration plus sensorielle et de fusion de capteurs, dit Nadel. Ce n’est pas ainsi que nous gagnons notre vie en tant que modèle d’entreprise. L’intention est de démontrer des systèmes de travail réels et tangibles à partir de notre technologie. L’idée était que nous pourrions les mettre entre les mains des gens et qu’ils pourraient voir ce que nous faisons.
BrainChips Akida IP prend en charge jusqu’à 1 024 nœuds pouvant être configurés en deux à 256 nœuds connectés sur un réseau maillé, chaque nœud comprenant quatre unités de traitement neuronal. Chacun des NPU comprend une SRAM configurable et chaque NPU peut être configuré pour les CNN si nécessaire et chacun est basé sur des événements ou des pics, en utilisant la rareté des données, les activations et les poids pour réduire le nombre d’opérations d’au moins deux fois. Le SoC Akida Neural peut être utilisé de manière autonome ou intégré en tant que coprocesseur dans une gamme de cas d’utilisation et fournit 1,2 million de neurones et 10 milliards de synapses.
L’offre comprend également le cadre d’apprentissage automatique MetaTF pour le développement de réseaux de neurones pour les applications de pointe et trois systèmes de développement de référence pour les systèmes PCI, PC shuttle et Raspberry Pi.
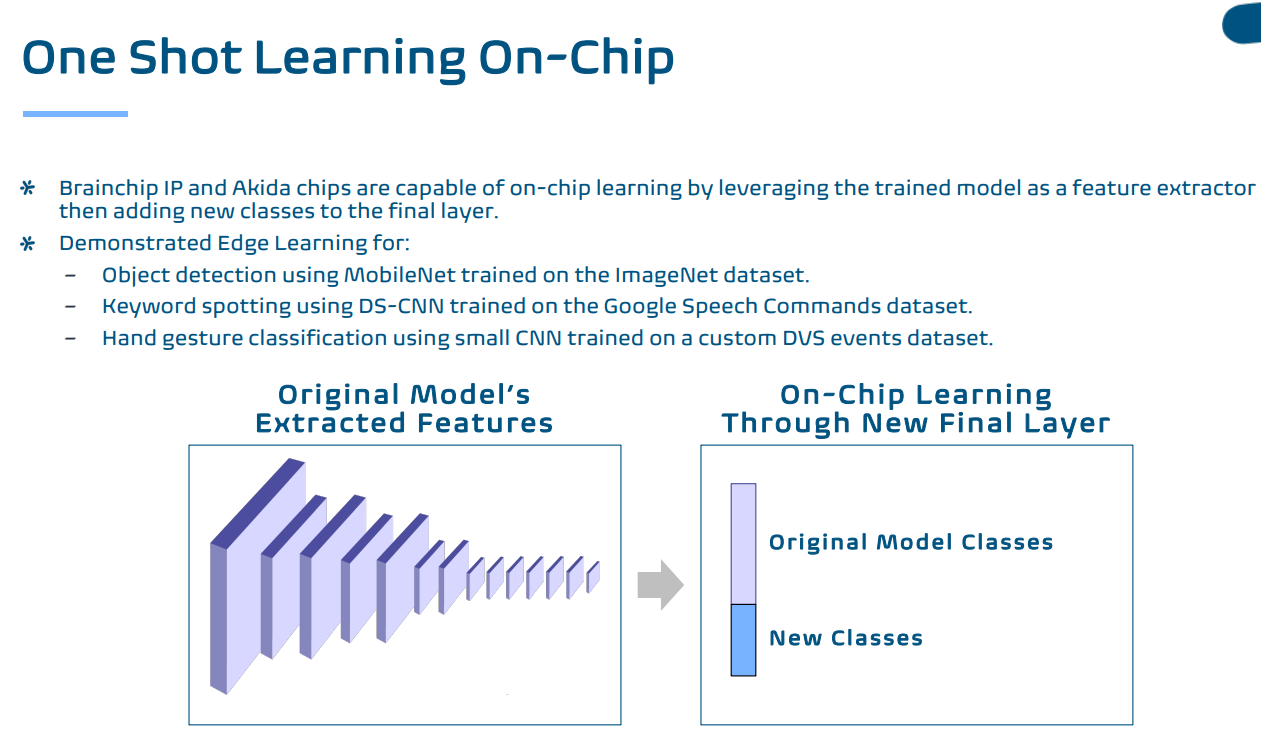
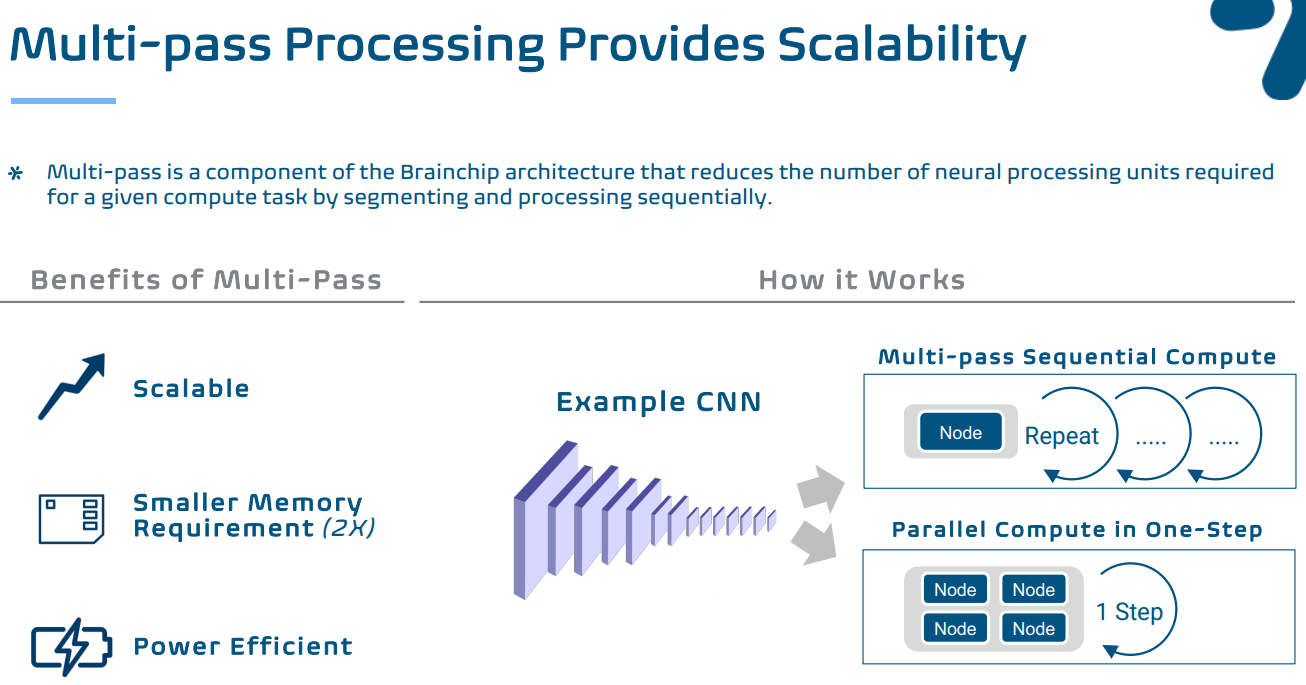
La plate-forme peut être utilisée pour un apprentissage sur puce unique en utilisant le modèle formé pour extraire des fonctionnalités et en y ajoutant de nouvelles classes ou dans un traitement multipasse qui exploite le traitement parallèle pour réduire le nombre de NPU nécessaires.
Voici le one shot :
Et il y a le multipass :
L’idée que notre accélérateur soit proche du capteur signifie que vous n’envoyez pas de données de capteur, vous envoyez des données d’inférence, a déclaré Nadel. C’est vraiment un jeu d’architecture de systèmes dans lequel nous envisageons que notre micro-matériel est associé à des capteurs. Le capteur capture les données, elles sont prétraitées. Nous faisons l’inférence à partir de cela et l’apprentissage au centre, mais surtout l’inférence. À l’instar d’un système avancé d’assistance à la conduite embarqué, vous ne chargez pas le serveur chargé de GPU de tous les calculs et inférences de données. Vous obtenez les données d’inférence, les métadonnées et votre charge sera plus légère.
Le traitement des données sur puce fait partie de la conviction de BrainChips que pour une grande partie de l’IA de pointe, l’avenir n’aura pas besoin de nuages. Plutôt que d’envoyer toutes les données vers le cloud, entraînant une latence et des coûts plus élevés, la clé fera tout sur la puce elle-même. Nadel dit que c’est un peu une provocation pour l’industrie des semi-conducteurs en parlant d’indépendance du cloud. Ce n’est pas anti-cloud, mais l’idée est que l’hyperscale jusqu’au bord est probablement la mauvaise approche. Vous devez remonter le capteur.
Revenir au cloud signifie également devoir recycler le modèle en cas de changement de classification des objets, explique Anil Mankar, co-fondateur et directeur du développement. La prochaine plateforme. Ajouter plus de classes signifie changer les poids dans la classification.
Apprentissage sur puce, dit Mankar. C’est ce qu’on appelle l’apprentissage incrémental ou l’apprentissage continu, et cela n’est possible que parce que nous travaillons avec des pointes et que nous copions en fait de la même manière la façon dont notre cerveau apprend les visages, les objets et des choses comme ça. Les gens ne veulent pas faire d’apprentissage par transfert, retourner dans le cloud, obtenir de nouveaux poids. Vous pouvez maintenant classer plus d’objets. Une fois que vous avez une activité sur l’appareil, vous n’avez pas besoin de cloud, vous n’avez pas besoin de revenir en arrière. Tout ce que vous apprenez, vous apprenez et cela ne change pas lorsque quelque chose de nouveau est ajouté.