
Le fabricant d’ordinateurs AI Graphcore dévoile une puce 3D et promet une machine «ultra-intelligence» de 500 billions de paramètres | ZDNet

Graphcore, le fabricant de puces et de systèmes d’intelligence artificielle basé à Bristol, en Angleterre, âgé de six ans, a annoncé jeudi une nouvelle puce appelée « Bow » qui utilise deux puces semi-conductrices empilées l’une sur l’autre. accélérera de 40 % les applications telles que l’apprentissage en profondeur tout en réduisant la consommation d’énergie.
La société a également annoncé des modèles mis à jour de ses ordinateurs multiprocesseurs, appelés « IPU-POD », exécutant la puce Bow, qui, selon elle, sont cinq fois plus rapides que les machines DGX comparables de Nvidia à la moitié du prix.
Dans un clin d’œil à la taille croissante des modèles de réseaux neuronaux d’apprentissage en profondeur tels que le Megatron-Turing, la société a déclaré qu’elle travaillait sur une conception informatique, appelée The Good Computer, qui sera capable de gérer des modèles de réseaux neuronaux qui utilisent 500 000 milliards de paramètres. , rendant possible ce qu’elle appelle une « ultra-intelligence » surhumaine.
Le processeur Bow est la dernière version de ce que Graphcore appelle les « IPU », pour Intelligence Processing Units. La société a déjà publié deux itérations d’IPU, la dernière étant fin 2020.
Bow, qui porte le nom du quartier Bow de Londres, est « la première étape de ce qui est pour nous une direction stratégique qui implique l’intégration verticale du silicium, en d’autres termes, l’empilement des matrices de silicium les unes sur les autres », a déclaré Simon Knowles, co -fondateur et technologue en chef de Graphcore, lors d’un point de presse.
Également: « C’est fondamental »: le PDG de Graphcore pense que de nouveaux types d’IA prouveront la valeur d’un nouveau type d’ordinateur
Semblable au « Wafer Scale Engine » développé par le concurrent Cerebras Systems, le Bow utilise de nouvelles techniques de fabrication qui vont au-delà de la fabrication conventionnelle des microprocesseurs.
Le Bow est la première puce à utiliser ce qu’on appelle la technologie de puce wafer-on-wafer, où deux puces sont liées ensemble. Il a été développé « en étroite collaboration » avec le géant de la fabrication de puces sous contrat Taiwan Semiconductor Manufacturing, a déclaré le CTO de Graphcore, Simon Knowles, lors d’un briefing pour les médias.

La puce peut effectuer 350 billions de virgule flottante par seconde d’arithmétique d’IA à précision mixte, a déclaré Knowles, qui, selon lui, a fait de la puce « le processeur d’IA le plus performant au monde aujourd’hui ».
La puce WSE-2 de Cerebras semble être plus rapide que cela, selon une estimation du bulletin technologique Microprocessor Report, qui affirme que le WSE-2 fournit jusqu’à 1 700 à 3 400 téraflops pour l’arithmétique à virgule flottante 32 bits ou 16 bits, respectivement. . Cependant, Graphcore maintient que la puce de Cerebras n’est pas une puce mais en fait une plaquette, car elle se compose de presque une plaquette semi-conductrice entière de 12 pouces et n’est donc pas comparable.
Le Bow utilise les mêmes 900 mégaoctets de cache principal SRAM sur puce et peut déplacer des données à 65 billions d’octets par seconde. Les liaisons entre les puces se déplacent à 320 gigaoctets par seconde.
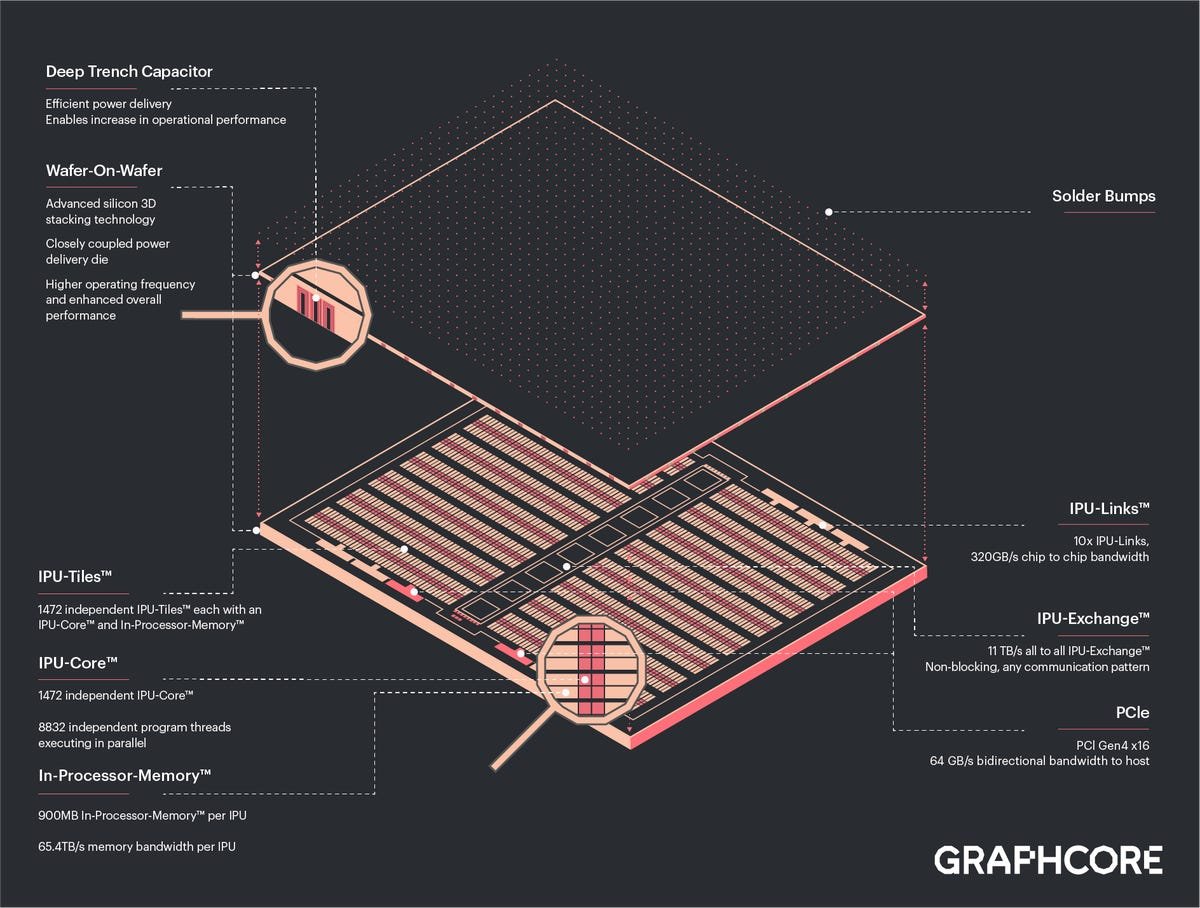

Le processus de fabrication de Bow implique la fusion de deux tranches avant que les tranches ne soient découpées en matrices séparées. Les puces sont assemblées via ce que l’on appelle la « liaison hybride », que Knowles a comparée à la soudure à froid. Il rejoint les circuits métalliques de chaque plaquette. La plaquette supérieure est ensuite rasée jusqu’à une qualité très fine, semblable à un film, qui est « disquette ». La plaquette inférieure porte le support structurel pour les deux.
Également: La startup de puces AI Graphcore entre dans le secteur des systèmes en revendiquant une économie bien meilleure que celle de Nvidia
Ce processus rend possible « une densité extrêmement élevée d’interconnexion entre les deux tranches », a déclaré Knowles.
Il est « plus sophistiqué », a-t-il dit, que les approches typiques « puce sur plaquette » utilisées, par exemple, par Advanced Micro Devices pour lier les circuits de mémoire à la puce logique. Par rapport à ce processus, la plaquette sur plaquette atteint dix fois la densité d’interconnexions, a-t-il déclaré.
Une technique supplémentaire dans l’arc est un « via » spécial, un tunnel qui relie le dé empilé au reste du système.
Le but de la matrice supérieure qui repose sur les circuits logiques et mémoire de l’IPU est d’alimenter les circuits. Ces « cellules de condensateur à tranchée profonde », comme on les appelle, sont similaires aux cellules de mémoire DRAM. Au lieu de stocker des informations, les cellules sont des « réservoirs de charge » qui accélèrent les transistors logiques. Cela augmente la vitesse d’horloge des transistors de 1,325 gigahertz à 1,85 gigahertz. Cela se traduit par une accélération de 40 %.
La nouvelle puce est compatible avec tous les systèmes Graphcore existants et l’environnement de programmation Poplar de la société, et son prix est le même que celui des modèles précédents.
La puce Bow améliorera la consommation d’énergie de 16%, a déclaré Graphcore.
Le Bow est assemblé dans des machines IPU-POD, appelées BOW POD, qui passent de 16 puces Bow à 1 024, fournissant jusqu’à 358,4 pétaflops de calcul, en conjonction avec jusqu’à 64 processeurs compagnons.

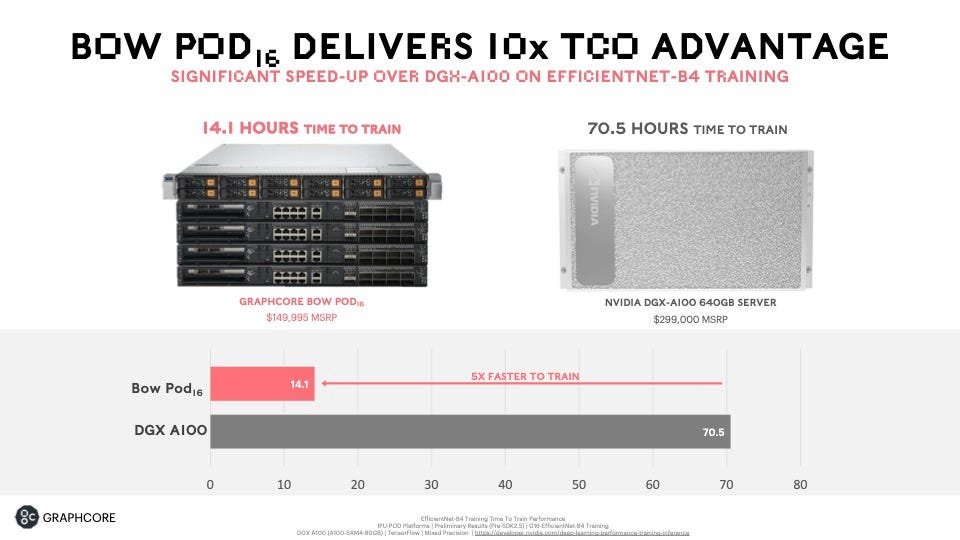
Graphcore, qui a démontré des métriques compétitives à Nvidia dans les tests de référence MLPERF, affirme que le BOW POD-16 peut offrir une vitesse cinq fois supérieure pour former le réseau neuronal EfficientNet par rapport à un serveur DGX-A100 comparable de Nvidia. Le coût du BOW POD-16 est la moitié de celui du DGX, selon Graphcore, 149 995 $ contre 299 000 $.
Également: La startup d’IA Graphcore dit que la plupart du monde ne formera pas l’IA, mais la distillera simplement
Les premiers clients des machines à pod basées sur Bow incluent Pacific Northwest National Labs, un laboratoire de recherche du département américain de l’énergie basé à Richland, Washington. PNNL utilise les machines pour exécuter des réseaux de neurones basés sur Transformer et des réseaux de neurones graphiques, pour des tâches telles que la chimie computationnelle et la cybersécurité.
Certains partenaires proposeront les Pods en tant que services cloud, notamment Kingsoft Cloud of China et Cirrascale.
Le co-fondateur et PDG de Graphcore, Nigel Toon, dans le même point de presse, a déclaré que l’approche plaquette sur plaquette de Bow rendra possible de nombreuses puces empilées qui augmenteront considérablement la puissance de calcul.
« Nous allons tirer parti de cette technologie wafer-on-wafer pour piloter la prochaine phase de l’informatique IA », a déclaré Toon.
Cette UIP de nouvelle génération, a-t-il dit, réaliserait la vision du scientifique en informatique des années 1960 Jack Good, un collègue d’Alan Turing qui a conçu une « explosion de l’intelligence ».

Good a été la première personne à « décrire l’idée qu’un ordinateur serait capable de dépasser la capacité de calcul et la capacité d’information d’un cerveau humain », a déclaré Toon. « Nous nous lançons maintenant, nous travaillons aujourd’hui sur un projet pour concrétiser cette idée d’ultra-intelligence. »
« Nous ne savons pas vraiment ce que cela signifie en termes de débit de calcul », a déclaré Knowles. Cependant, il existe quelques centaines de milliards de synapses dans le cerveau humain.
Ces synapses sont « très similaires aux paramètres appris par un réseau de neurones artificiels ». Les réseaux de neurones d’aujourd’hui se sont rapprochés d’un billion, a-t-il noté, « il nous reste donc clairement deux ordres de grandeur ou plus à parcourir avant de réussir à construire un réseau de neurones artificiels doté d’une capacité paramétrique similaire à celle d’un cerveau humain.
Également: Graphcore apporte une nouvelle concurrence à Nvidia dans les derniers benchmarks MLPerf AI
« C’est ce que nous annonçons aujourd’hui », a déclaré Knowles. « Une machine qui dépassera en fait la capacité paramétrique du cerveau humain. »
« Ce n’est pas une idée de rêve, c’est un produit », a déclaré Knowles. « C’est quelque chose que nous avons décidé de livrer parce que nos clients l’ont demandé.
« Ce n’est pas destiné à être unique [] et nous avons l’intention d’en fabriquer beaucoup et de les vendre à nos clients. »
Le bon ordinateur combinera plusieurs tranches de circuits logiques, réalisant 10 exaflops de calcul, 10 milliards de milliards d’opérations en virgule flottante par seconde, alimentées par quatre pétaoctets de mémoire.
« Nous espérons être en mesure de fournir cette technologie en tant que produit pour environ 120 millions de dollars », a-t-il déclaré. « C’est beaucoup d’argent, mais en fait, beaucoup moins que la plupart des supercalculateurs d’aujourd’hui. »
Knowles a reconnu que des réseaux de neurones de plus en plus grands imposeront à l’avenir une plus grande demande d’interconnexions puce à puce. « Au fur et à mesure que les structures des modèles s’enrichissent et qu’elles commencent à ressembler davantage à des graphiques, dans un sens, il y aura une pression constante sur la bande passante inter-puces, et c’est certainement un facteur dans notre réflexion architecturale pour la suite. génération. »