
CXL apporte l’informatique de la taille d’un centre de données avec la norme 3.0, pense à la 4.0
Une nouvelle version d’une norme soutenue par les principaux fournisseurs de cloud et les sociétés de puces pourrait changer la façon dont certains des plus grands centres de données et des supercalculateurs les plus rapides du monde sont construits.
 Le consortium CXL a annoncé mardi une nouvelle spécification appelée CXL 3.0, également connue sous le nom de Compute Express Link 3.0, qui élimine davantage de points d’étranglement qui ralentissent le calcul dans l’informatique d’entreprise et les centres de données.
Le consortium CXL a annoncé mardi une nouvelle spécification appelée CXL 3.0, également connue sous le nom de Compute Express Link 3.0, qui élimine davantage de points d’étranglement qui ralentissent le calcul dans l’informatique d’entreprise et les centres de données.
La nouvelle spécification fournit un lien de communication entre les puces, la mémoire et le stockage dans les systèmes, et elle est deux fois plus rapide que son prédécesseur appelé CXL 2.0.
CXL 3.0 présente également des améliorations pour une mise en commun et un partage plus précis des ressources informatiques pour des applications telles que l’intelligence artificielle.
CXL 3.0 vise à améliorer la bande passante et la capacité, et peut mieux provisionner et gérer les ressources de calcul, de mémoire et de stockage, a déclaré Kurt Lender, coprésident du groupe de travail marketing CXL (et responsable principal de l’écosystème chez Intel), dans une interview avec HPCwire.
Les fournisseurs de matériel et de cloud fusionnent autour de CXL, qui a écrasé d’autres interconnexions concurrentes. Cette semaine, OpenCAPI, une norme d’interconnexion soutenue par IBM, a fusionné avec CXL Consortium, suivant les traces de Gen-Z, qui a fait de même en 2020.
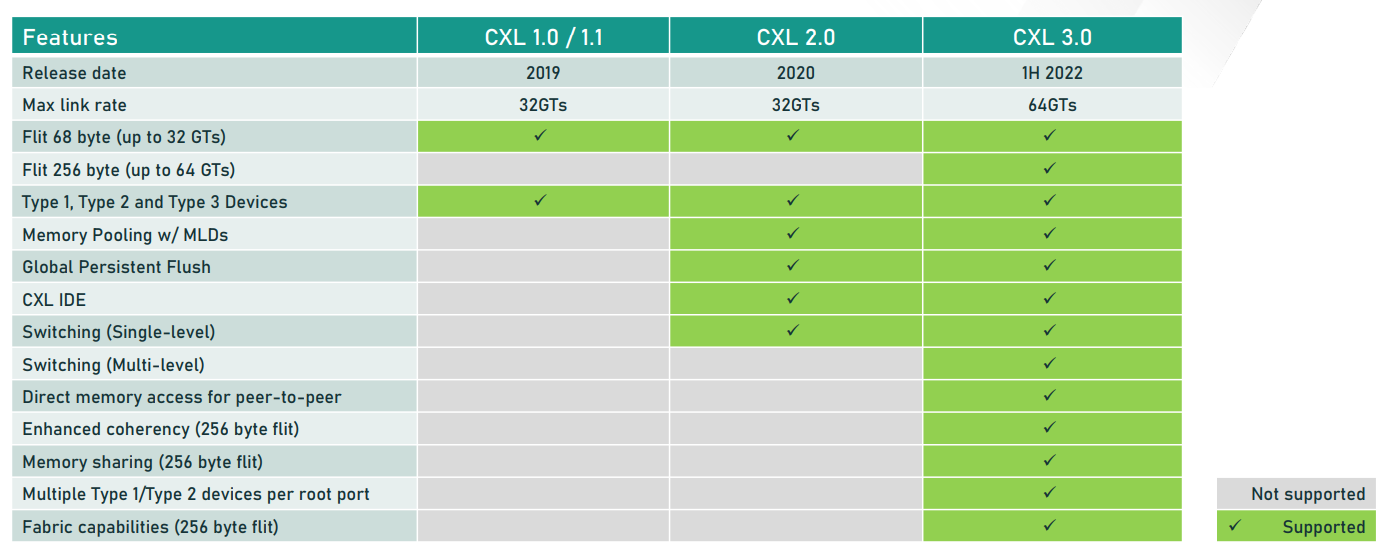
CXL a publié la première spécification CXL 1.0 en 2019, et l’a rapidement suivie avec CXL 2.0, qui prenait en charge PCIe 5.0, qui se trouve dans une poignée de puces telles que Sapphire Rapids d’Intel et le GPU Hopper de Nvidia.
La spécification CXL 3.0 est basée sur PCIe 6.0, qui a été finalisée en janvier. CXL a une vitesse de transfert de données allant jusqu’à 64 gigatransferts par seconde, ce qui est identique à PCIe 6.0.
L’interconnexion CXL peut relier des puces, du stockage et de la mémoire proches et éloignés les uns des autres, ce qui permet aux fournisseurs de systèmes de construire des centres de données comme un système géant, a déclaré Nathan Brookwood, analyste principal chez Insight 64.
La capacité de CXL à prendre en charge l’expansion de la mémoire, du stockage et du traitement dans une infrastructure désagrégée donne au protocole un pas en avant par rapport aux normes concurrentes, a déclaré Brookwood.
Les infrastructures des centres de données évoluent vers une structure découplée pour répondre aux besoins croissants de traitement et de bande passante pour les applications d’IA et graphiques, qui nécessitent de grands pools de mémoire et de stockage. Les systèmes d’IA et de calcul scientifique nécessitent également des processeurs au-delà des processeurs, et les organisations installent des boîtiers d’IA et, dans certains cas, des ordinateurs quantiques, pour plus de puissance.
CXL 3.0 améliore la bande passante et la capacité grâce à de meilleures technologies de commutation et de structure, a déclaré le prêteur du consortium CXL.
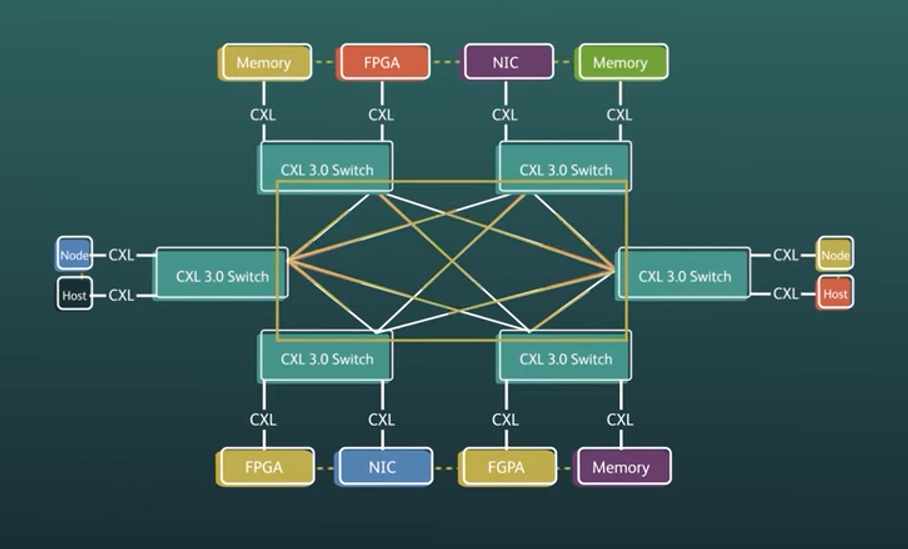
« CXL 1.1 était en quelque sorte dans le nœud, puis avec 2.0, vous pouvez vous étendre un peu plus dans le centre de données. Et maintenant, vous pouvez réellement parcourir les racks, vous pouvez créer des systèmes décomposables ou composables, avec la… technologie de tissu que nous avons apportée avec CXL 3.0 », a déclaré Lender.
Au niveau du rack, on peut créer des tiroirs CPU ou mémoire en tant que systèmes séparés, et les améliorations de CXL 3.0 offrent plus de flexibilité et d’options dans la commutation des ressources par rapport aux spécifications CXL précédentes.
En règle générale, les serveurs disposent d’un processeur, d’une mémoire et d’E/S, et leur expansion physique peut être limitée. Dans une infrastructure désagrégée, on peut amener un câble vers un plateau de mémoire séparé via un protocole CXL sans compter sur le bus DDR populaire.
« Vous pouvez décomposer ou composer votre datacenter comme bon vous semble. Vous avez la capacité de déplacer des ressources d’un nœud à un autre, et vous n’avez pas à faire autant de surprovisionnement que nous le faisons aujourd’hui, en particulier avec la mémoire », a déclaré Lender, ajoutant« il s’agit de développer des systèmes et une sorte d’interconnexion maintenant à travers ce tissu et à travers CXL.
Le protocole CXL 3.0 utilise les composants électriques du protocole PCI-Express 6.0, ainsi que ses protocoles d’E/S et de mémoire. Certaines améliorations incluent la prise en charge de nouveaux processeurs et terminaux qui peuvent tirer parti de la nouvelle bande passante. CXL 2.0 avait une commutation à un seul niveau, tandis que 3.0 a une commutation à plusieurs niveaux, ce qui offre plus de latence sur la structure.
« Vous pouvez réellement commencer à regarder la mémoire comme un stockage, vous pourriez avoir une mémoire chaude et une mémoire froide, etc. Vous pouvez avoir différents niveaux et les applications peuvent en tirer parti », a déclaré Lender.
Le protocole tient également compte de l’infrastructure en constante évolution des centres de données, offrant plus de flexibilité sur la manière dont les administrateurs système souhaitent agréger et désagréger les unités de traitement, la mémoire et le stockage. Le nouveau protocole ouvre plus de canaux et de ressources pour les nouveaux types de puces qui incluent les SmartNIC, les FPGA et les IPU qui peuvent nécessiter un accès à plus de ressources de mémoire et de stockage dans les centres de données.
« Systèmes composables HPC… vous n’êtes pas limité par une boîte. Le HPC adore les clusters aujourd’hui. Et [with CXL 3.0] maintenant vous pouvez faire des clusters cohérents et une faible latence. La croissance et la flexibilité de ces nœuds se développent rapidement », a déclaré Lender.
Le protocole CXL 3.0 peut prendre en charge jusqu’à 4 096 nœuds et dispose d’un nouveau concept de partage de mémoire entre différents nœuds. Il s’agit d’une amélioration par rapport à une configuration statique dans les anciens protocoles CXL, où la mémoire pouvait être découpée en tranches et attachée à différents hôtes, mais ne pouvait pas être partagée une fois allouée.
« Nous avons maintenant un partage où plusieurs hôtes peuvent réellement partager un segment de mémoire. Désormais, vous pouvez réellement envisager un mouvement de données rapide et efficace entre les hôtes si nécessaire, ou si vous avez une application de type IA que vous souhaitez transmettre des données d’un processeur ou d’un hôte à un autre », a déclaré Lender.
La nouvelle fonctionnalité permet une connexion peer-to-peer entre les nœuds et les points de terminaison dans un seul domaine. Cela met en place un mur dans lequel le trafic peut être isolé pour se déplacer uniquement entre les nœuds connectés les uns aux autres. Cela permet un transfert de données plus rapide d’accélérateur à accélérateur ou d’appareil à appareil, ce qui est essentiel pour créer un système cohérent.
« Si vous pensez à certaines applications, puis à certains GPU et différents accélérateurs, ils veulent transmettre rapidement des informations, et maintenant ils doivent passer par le CPU. Avec CXL 3.0, ils n’ont pas à passer par le CPU de cette façon, mais le CPU est cohérent, conscient de ce qui se passe », a déclaré Lender.
La mise en commun et l’allocation des ressources mémoire sont gérées par un logiciel appelé Fabric Manager. Le logiciel peut se trouver n’importe où dans le système ou sur les hôtes pour contrôler et allouer de la mémoire, mais cela pourrait finalement avoir un impact sur les développeurs de logiciels.
« Si vous arrivez au niveau de la hiérarchisation, et lorsque vous commencez à avoir toutes les latences différentes dans la commutation, c’est là qu’il devra y avoir une certaine sensibilisation et un réglage de l’application. Je pense que nous avons certainement cette capacité aujourd’hui », a déclaré Lender.
Il pourrait s’écouler deux à quatre ans avant que les entreprises ne commencent à lancer les produits CXL 3.0, et les processeurs devront être conscients de CXL 3.0, a déclaré Lender. Intel a intégré la prise en charge de CXL 1.1 dans sa puce Sapphire Rapids, qui devrait commencer à être expédiée en volume plus tard cette année. Le protocole CXL 3.0 est rétrocompatible avec les anciennes versions de la norme d’interconnexion.
Les produits CXL basés sur des protocoles antérieurs arrivent lentement sur le marché. SK Hynix a présenté cette semaine ses premiers échantillons de mémoire DDR5 DRAM CXL (Compute Express Link) et commencera à fabriquer des modules de mémoire CXL en volume l’année prochaine. Samsung a également introduit CXL DRAM plus tôt cette année.
Alors que les produits basés sur les protocoles CXL 1.1 et 2.0 sont sur un cycle de sortie de produit de deux à trois ans, les produits CXL 3.0 pourraient prendre un peu plus de temps car ils adoptent un environnement informatique plus complexe.
CXL 3.0 pourrait en fait être un peu plus lent à cause de certains Fabric Manager, le logiciel fonctionne. Ce ne sont pas des systèmes simples lorsque vous commencez à vous lancer dans les tissus, les gens voudront d’abord faire une preuve de concept et prouver la technologie. Ce sera probablement un délai de trois à quatre ans », a déclaré Lender.
Certaines entreprises ont déjà commencé à travailler sur l’IP de vérification CXL 3.0 il y a six à neuf mois et affinent les outils pour la spécification finale, a déclaré Bender.

Le CXL a une réunion du conseil d’administration en octobre pour discuter des prochaines étapes, qui pourraient également impliquer CXL 4.0. L’organisation de normalisation pour PCIe, appelée PCI-Special Interest Group, a annoncé le mois dernier qu’elle prévoyait PCIe 7.0, qui augmente la vitesse de transfert de données à 128 gigatransferts par seconde, soit le double de celle de PCIe 6.0.
Le prêteur était prudent quant à la façon dont PCIe 7.0 pourrait potentiellement s’intégrer dans un CXL 4.0 de nouvelle génération. CXL possède son propre ensemble de protocoles d’E/S, de mémoire et de cache.
« CXL repose sur les composants électriques de PCIe, je ne peux donc pas m’engager ou garantir absolument que [CXL 4.0] fonctionnera sur 7.0. Mais c’est l’intention – d’utiliser l’électricité », a déclaré Lender.
Dans ce cas, l’un des principes de CXL 4.0 sera de doubler la bande passante en passant à PCIe 7.0, mais « au-delà de cela, tout le reste sera ce que nous ferons de plus de tissu ou de réglages différents », a déclaré Lender.
CXL a connu un rythme accéléré, avec trois versions de spécifications depuis sa création en 2019. Il y avait une confusion dans l’industrie sur le meilleur bus d’E/S cohérent à grande vitesse, mais l’attention s’est maintenant coagulée autour de CXL.
« Maintenant, nous avons le tissu. Il y a des morceaux de Gen-Z et d’OpenCAPI qui ne sont même pas dans CXL 3.0, alors allons-nous les incorporer ? Bien sûr, nous allons envisager de faire ce genre de travail à l’avenir », a déclaré Lender.