
Comment les hautes performances et le calcul scientifique bénéficient du moteur de services distribués de vSphere 8 – Bureau du blog du CTO
La technologie des centres de données évolue sur plusieurs fronts, du stockage plus rapide basé sur NVMe, à un nombre accru de cœurs d’unité centrale de traitement (CPU) et de mémoire système à des interconnexions plus rapides telles que 400GbE. Ces innovations sont adoptées par des applications et des plates-formes telles que le Big Data, le HPC et l’IA/ML, repoussant les limites pour obtenir les meilleures performances possibles. Bon nombre de ces nouvelles applications et plates-formes bénéficient non seulement d’interconnexions plus rapides, d’un stockage avec une latence plus faible ou d’une plus grande puissance de calcul, mais également de déchargements matériels tels que les GPU et les FPGA.
Dans l’architecture actuelle du centre de données, la CPU supervise, coordonne et contrôle la plupart des fonctionnalités et des capacités des services définis par le matériel et le logiciel qui s’exécutent sur les systèmes d’exploitation (par exemple, NSX). Malheureusement, cette approche centrée sur le processeur s’est avérée créer un goulot d’étranglement pour les architectures à l’échelle.
Nous devons commencer à changer l’approche de conception des centres de données définis par logiciel en une approche qui associe étroitement le matériel aux systèmes d’exploitation. Une bonne approche consisterait à décharger un plan de gestion spécifique, la mise en réseau, les services de sécurité, le stockage, etc., sur du matériel dédié, libérant ainsi efficacement les ressources des cœurs de processeur x86 plus chers pour les charges de travail de production et offrant d’autres avantages, tels que l’isolation de la sécurité.
Cet article discutera des avantages de l’exploitation des unités de traitement de données (DPU) avec la dernière version de vSphere 8.0 et comment cela profitera à l’exécution des charges de travail scientifiques et de recherche.
Qu’est-ce qu’un DPU ?
Un DPU est un système sur puce (SoC) programmable doté d’un processeur standard (basé sur ARM dans la plupart des cas), de plusieurs moteurs d’accélération programmables et d’interfaces réseau hautes performances.
Avec l’introduction récente de vSphere 8.0, nous avons vu le nouveau vSphere Distributed Services Engine, qui tire parti de ces DPU sous la forme d’un SmartNIC, offrant de multiples fonctionnalités comme le déchargement vSwitch, l’isolation sécurisée (démarrage sécurisé, racine de confiance, etc.) , déchargement de la superposition réseau, RDMA et accélérateurs de synchronisation de précision pour les charges de travail telco/NFV. En outre, ils sont également capables d’exécuter des systèmes d’exploitation ou des applications/charges de travail à usage général.
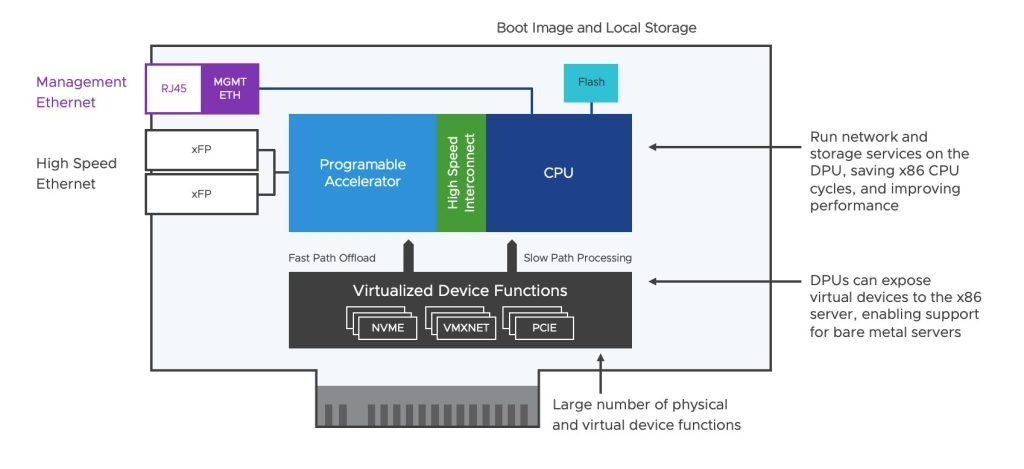
La plupart des DPU de la génération actuelle sont entièrement équipés d’un stockage persistant local intégré, d’une grande quantité de RAM DDR, de caches à plusieurs niveaux, d’un complexe racine PCIe, de fonctions de périphérique virtualisé (VF – SR-IOV) et de capacités d’E/S. Pour cette raison, les DPU pourraient être utilisés pour de nombreux autres cas d’utilisation au-delà de l’accélération du réseau et de la sécurité.
Moteur de services distribués vSphere
vSphere Distributed Services Engine introduit plusieurs modifications du point de vue d’ESXi. Cela inclut une instance d’ESXi s’exécutant directement sur le DPU, permettant de nombreux cas d’utilisation comme le déchargement direct de l’accélération du réseau sur le DPU. La communication entre l’ESXi principal (installé sur x86) et la deuxième instance d’ESXi exécutée sur le DPU se produit sur un canal IPV4 privé. Cette approche libère des ressources des processeurs x86 et fournit une ligne de démarcation claire entre les charges de travail productives (exécutées sur des machines virtuelles et des conteneurs) et l’infrastructure, servant de couche d’isolation, réduisant la possibilité que les services d’infrastructure soient affectés par toute éventuelle violation de sécurité qui s’est produite sur les charges de travail en cours d’exécution.

La première phase de vSphere Distributed Services Engine introduit le déchargement du traitement réseau avec EDP (chemin de données amélioré), ce qui signifie que le chemin de données lui-même sera optimisé. Cela ouvre également la possibilité d’accélérer les services de routage distribué NSX, DFW et les services de sécurité tels que IDP/IDS en les exécutant directement sur le DPU (nécessite une licence d’entreprise NSX). L’EDP n’est pas nouveau; ce mode de pile réseau est utilisé pour NFV et d’autres types de charges de travail qui peuvent bénéficier d’une latence plus faible et d’un débit plus élevé, mais nécessitent toujours des ressources CPU du serveur x86 pour y parvenir (en réservant effectivement des cœurs pour ce mode de chemin de données). En tirant parti d’un DPU, nous pouvons à la place utiliser les unités de traitement ARM à cette fin.
EDP peut être utilisé conjointement avec UPTv2 pour fournir le meilleur des deux mondes, un chemin de données accéléré avec contournement de l’hyperviseur, mais sans sacrifier les fonctionnalités de gestion de la charge de travail telles que DRS, HA et vMotion qui ne peuvent pas être utilisées avec les technologies de relais existantes telles que SR-IOV. Cependant, les exigences UPTv2 sont strictes, nécessitant une réservation complète de mémoire VM et une version de pilote VMXNET3 spécifique.
UPTv2 n’est pas le seul mode à fonctionner avec EDP. Nous pouvons également tirer parti du mode MUX, qui, bien qu’il ne s’agisse pas d’un relais hyperviseur complet comme avec UTPv2, MUX n’impose pas les mêmes exigences rigoureuses. Bien que le mode MUX soit le mode par défaut, ce mode utilise toujours une partie de la puissance de traitement x86 pour le balisage des paquets TX/RX, donc pour obtenir les meilleures performances, nous devrions regarder UTPv2.
Comment les hautes performances et le calcul scientifique peuvent bénéficier d’un moteur de services distribués
Comme déjà mentionné, une architecture centrée sur le processeur présente de multiples inconvénients, augmentés par les tendances macro de l’industrie telles que :
- Les données que nous générons croissent à un rythme très accéléré.
- La loi Moores ne tient plus et nous constatons un ralentissement de l’amélioration des performances de stockage, de mise en réseau et de calcul.
- La croissance du trafic intra-centre de données (est-ouest) est en croissance exponentielle.
Ces tendances montrent clairement qu’il est de plus en plus nécessaire de passer des architectures centrées sur le processeur à une approche d’architecture désagrégée pour des composants tels que le réseau, le stockage et les GPU. Permettre aux entreprises de rapprocher les ressources des charges de travail à la demande se traduira par une meilleure planification des ressources pour une évolutivité future et une gestion séparée du cycle de vie des services d’infrastructure et des domaines de charge de travail.
Les architectures désagrégées peuvent bénéficier des DPU de plusieurs manières :
- Déchargement des charges de travail des processeurs x86
- Les services d’infrastructure tels que le stockage défini par logiciel (vSAN), le traitement des E/S réseau, les services de sécurité (NSX et tiers) n’ont plus besoin de rivaliser avec les charges de travail de production puisque ces services sont exécutés sur le DPU.
- Une posture de sécurité commune sur plusieurs plates-formes Les DPU permettront à VMware d’exécuter indépendamment les services de sécurité NSX comme DFW sur une plate-forme commune. Si nous parlons de machines virtuelles, de conteneurs ou d’environnements bare metal, tout trafic entrant et sortant de l’hôte est inspecté au niveau du DPU, ce qui simplifie la conception, la mise en œuvre et l’adoption d’une nouvelle posture de sécurité commune sur différentes plates-formes et clouds.
- Amélioration des performances du réseau En tirant parti de l’EDP (en mode MUX ou UPTv2) et en disposant de ressources dédiées du DPU pour des fonctionnalités telles que le traitement des paquets, les superpositions, les inspections de sécurité, etc., nous serons en mesure de suivre le rythme de la croissance du trafic (et de son services associés) déjà en cours dans le centre de données.
- Les DPU d’accélération du stockage permettront un large éventail de cas d’utilisation du stockage tels que le déchargement de l’initiateur NVMe-oF (DPU prenant le rôle d’initiateur), le déchargement PSA, etc. Il est important de noter que la première phase de vSphere Distributed Services Engine ne couvre aucun des ces utilisations pour le moment mais finiront par intégrer de nouvelles fonctionnalités.
Ces avantages auront clairement un impact sur les performances des plates-formes HPC, ML, AI, NFV virtualisées et d’autres plates-formes telles que HFT, où la latence et les performances sont essentielles pour les opérations commerciales. Restez à l’affût des futures études de tests de performance que nous publierons.
Comment tirer parti d’EDP avec des hôtes compatibles DPU
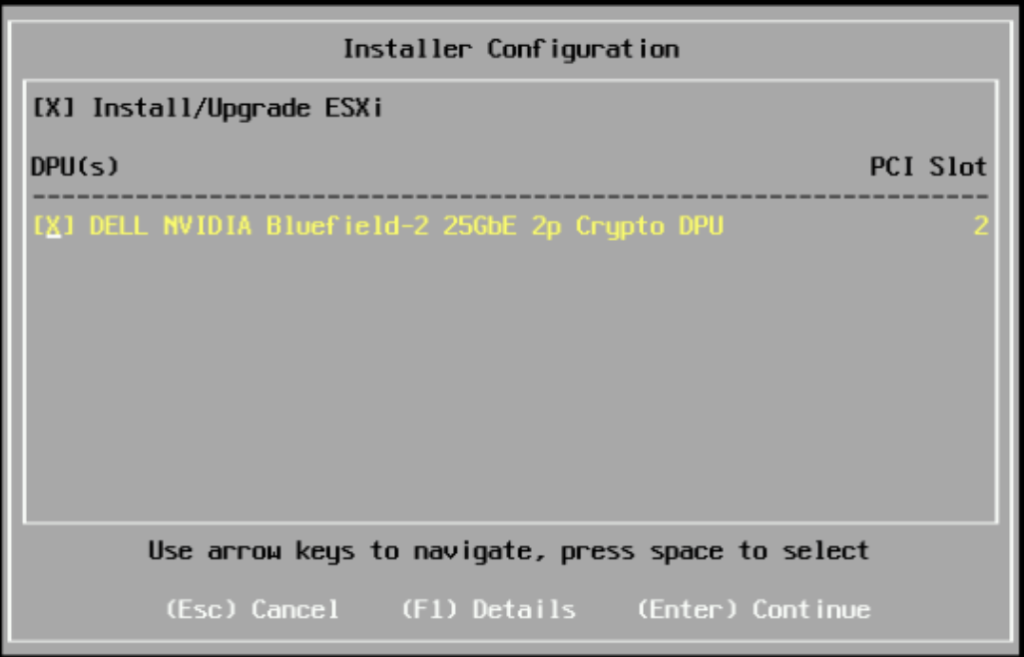
La première étape consiste à effectuer une installation ESXi unifiée ; cela installera ESXi sur votre serveur x86 et les DPU disponibles :
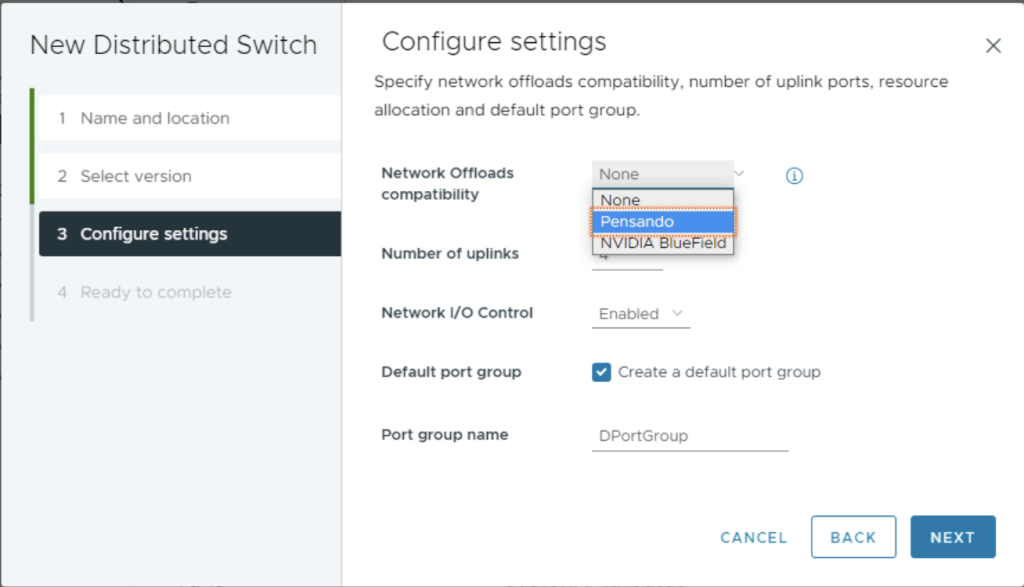
Une fois vos serveurs ESXi prêts, nous devons créer un commutateur distribué version 8.0 et sélectionner la bonne compatibilité de déchargement réseau (NVIDIA Bluefield ou AMD Pensando).
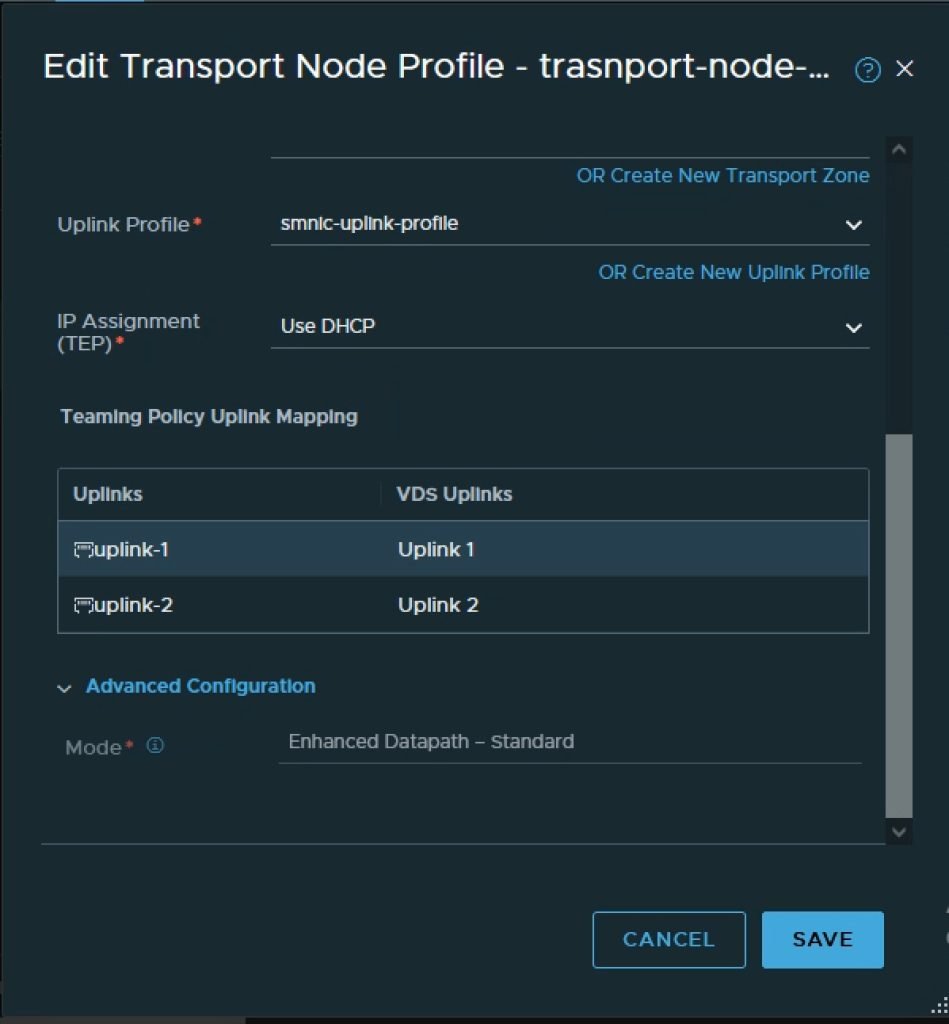
Ensuite, nous devons préparer les DPU dans le cadre de NSX-T Fabric, ce qui signifie que NSX-T Manager installera les composants NSX dans l’ESXi exécuté dans la DPU. Cela peut être accompli avec vLCM si nécessaire. Dans le cadre de ce processus, nous utiliserons un profil de nœud de transport dans lequel le mode de chemin de données requis est défini.
Une fois que la structure est prête, nous pouvons commencer à bénéficier des avantages du déchargement DPU. Si UPTv2 est requis, les paramètres de la VM doivent être modifiés en sélectionnant Utiliser le support UPT sous la vNIC.
Conclusion
Avec cette première phase de vSphere Distributed Services Engine, nous commençons à évoluer vers un modèle d’architecture désagrégée. Les ressources telles que le GPU sont regroupées et consommées à la demande, tandis que les services de réseau et de sécurité sont extraits de l’architecture centrée sur le processeur et exécutés sur les DPU. Cela permet en fin de compte à votre centre de données d’évoluer et de s’adapter aux demandes et aux modèles d’exploitation sans cesse croissants de l’industrie.
Les futures versions de Distributed Services Engine apporteront de nouvelles fonctionnalités intéressantes à vSphere, telles que l’exécution de DPU en tant que nœuds de transport NSX, laissant les ressources de calcul x86 intactes pour les charges de travail bare metal telles que HPC. Cela permettra aux chercheurs de consommer différents types de plates-formes de calcul en fonction des exigences spécifiques, des machines virtuelles, des conteneurs ou des serveurs Bare Metal avec le même cadre de gestion, la même posture de sécurité et les mêmes services réseau.