L’IA dans l’ingénierie logicielle chez Google : progrès et voie à suivre
Progrès de l’assistance basée sur l’IA pour l’ingénierie logicielle dans les outils internes de Google et nos projections pour l’avenir.
En 2019, un ingénieur logiciel chez Google ou ailleurs aurait entendu parler des progrès de l’apprentissage automatique et de la façon dont l’apprentissage profond est devenu remarquablement efficace dans des domaines tels que la vision par ordinateur ou la traduction linguistique. Cependant, la plupart d’entre eux n’auraient pas imaginé, et encore moins expérimenté, les bénéfices que l’apprentissage automatique pourrait apporter à leurs clients. ils faire.
À peine cinq ans plus tard, en 2024, les ingénieurs logiciels sont enthousiasmés par la façon dont l’IA aide à écrire du code. Et un nombre important d’entre eux ont utilisé la saisie semi-automatique basée sur le ML, qu’il s’agisse d’outils internes de grandes entreprises, par exemple la saisie semi-automatique de Google, ou via des produits disponibles dans le commerce.
Dans ce blog, nous présentons nos dernières améliorations basées sur l’IA dans le contexte de la transformation continue des outils de développement logiciel internes de Google, et discutons des autres changements que nous prévoyons de voir dans les 5 prochaines années. Nous présentons également notre méthodologie sur la manière de créer des produits d’IA qui apportent de la valeur au développement de logiciels professionnels. Notre équipe est responsable des environnements de développement logiciel dans lesquels les ingénieurs de Google passent la majorité de leur temps, notamment Boucle intérieure (par exemple, IDE, révision de code, recherche de code), ainsi que boucle externe surfaces (par exemple, gestion des bogues, planification). Nous montrons que les améliorations apportées à ces surfaces peuvent avoir un impact direct sur la productivité et la satisfaction des développeurs, deux mesures que nous surveillons attentivement.
Le défi
Un défi permanent dans ce domaine est que la technologie de l’IA évolue rapidement et qu’il est difficile de prédire quelles idées explorer en premier. Il existe souvent un écart important entre les démonstrations techniquement réalisables et une production réussie. Nous abordons le déploiement des idées dans les produits selon trois lignes directrices :
- Prioriser par faisabilité technique et impact: Travailler sur des idées dont la faisabilité technique a déjà été établie et dont un impact élevé (mesurable) sur les flux de travail des ingénieurs est attendu.
- Apprenez rapidement pour améliorer l’UX et la qualité des modèles: Concentrez-vous sur l’itération rapide et l’extraction des leçons apprises, tout en préservant la productivité et le bonheur des développeurs. L’expérience utilisateur est tout aussi importante que la qualité du modèle.
- Mesurer l’efficacité: Comme notre objectif est d’augmenter les indicateurs de productivité et de satisfaction, nous devons surveiller de manière approfondie ces indicateurs.
Appliquer les LLM au développement de logiciels
Avec l’avènement des architectures de transformateurs, nous avons commencé à explorer comment appliquer les LLM au développement de logiciels. La complétion de code en ligne basée sur LLM est l’application la plus populaire de l’IA appliquée au développement de logiciels : c’est une application naturelle de la technologie LLM que d’utiliser le code lui-même comme données de formation. L’UX semble naturel pour les développeurs puisque la saisie semi-automatique au niveau des mots est une fonctionnalité essentielle des IDE depuis de nombreuses années. Il est également possible d’utiliser une mesure approximative de l’impact, par exemple le pourcentage de nouveaux caractères écrits par l’IA. Pour ces raisons et bien d’autres, il était logique que cette application des LLM soit la première à être déployée.
Notre blog précédent décrit les façons dont nous améliorons l’expérience utilisateur grâce à la complétion du code et comment nous mesurons l’impact. Depuis lors, nous avons assisté à une croissance rapide et continue, similaire à d’autres contextes d’entreprise, avec un taux d’acceptation par les ingénieurs logiciels de 37 %.
Les principales améliorations proviennent à la fois des modèles plus grands avec des capacités de codage améliorées, des heuristiques pour construire le contexte fourni au modèle, ainsi que du réglage des modèles sur les journaux d’utilisation contenant les acceptations, les rejets et les corrections et de l’UX. Ce cycle est essentiel pour apprendre à partir de comportements pratiques plutôt que de formulations synthétiques.

Améliorer les fonctionnalités basées sur l’IA dans les outils de codage (par exemple, dans l’IDE) avec des données historiques de haute qualité sur tous les outils et avec des données d’utilisation capturant les préférences et les besoins des utilisateurs.
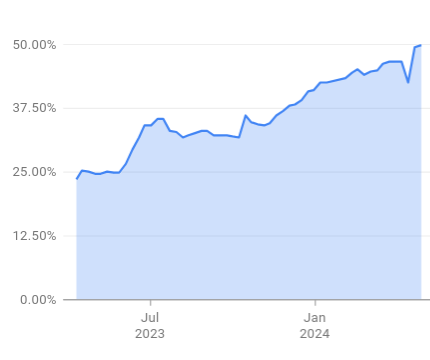
Augmentation continue de la fraction de code créé avec l’aide de l’IA via la complétion du code, définie comme le nombre de caractères acceptés à partir des suggestions basées sur l’IA divisé par la somme des caractères saisis manuellement et des caractères acceptés à partir des suggestions basées sur l’IA. Notamment, les caractères issus des copier-coller ne sont pas inclus dans le dénominateur.

Augmentation continue de la fraction de code créé avec l’aide de l’IA via la complétion du code, définie comme le nombre de caractères acceptés à partir des suggestions basées sur l’IA divisé par la somme des caractères saisis manuellement et des caractères acceptés à partir des suggestions basées sur l’IA. Notamment, les caractères issus des copier-coller ne sont pas inclus dans le dénominateur.
Nous utilisons nos journaux complets et de haute qualité sur les activités internes d’ingénierie logicielle dans plusieurs outils, que nous avons organisés pendant de nombreuses années. Ces données, par exemple, nous permettent de représenter des modifications de code plus fines, des résultats de build, des modifications pour résoudre des problèmes de build, des actions de copier-coller de code, des corrections de code collé, des révisions de code, des modifications pour résoudre des problèmes de réviseur et de modifier les soumissions en un dépôt. Les données de formation sont un corpus de code aligné avec des annotations spécifiques aux tâches en entrée et en sortie. La conception du processus de collecte de données, la forme des données d’entraînement et le modèle formé sur ces données ont été décrits dans notre blog DIDACT. Nous continuons à explorer ces puissants ensembles de données avec de nouvelles générations de modèles de fondation à notre disposition (discutés plus en détail ci-dessous).
Nos prochains déploiements importants ont consisté à résoudre les commentaires de révision de code (dont plus de 8 % sont désormais traités avec une assistance basée sur l’IA) et à adapter automatiquement le code collé au contexte environnant (désormais responsable d’environ 2 % du code dans l’IDE2). D’autres déploiements incluent l’instruction à l’EDI d’effectuer des modifications de code en langage naturel et la prévision des correctifs en cas d’échecs de construction. D’autres applications, par exemple la prédiction d’astuces pour la lisibilité du code suivant un modèle similaire, sont également possibles.
Ensemble, ces applications déployées constituent des applications performantes et très utilisées chez Google, avec un impact mesurable sur la productivité dans un contexte industriel réel.
Une démonstration de la manière dont diverses fonctionnalités basées sur l’IA peuvent fonctionner ensemble pour faciliter le codage dans l’EDI.
Ce que nous avons appris
Notre travail jusqu’à présent nous a appris plusieurs choses :
- Nous avons atteint le plus haut impact avec une UX qui s’intègre naturellement dans les flux de travail des utilisateurs. Dans tous les exemples ci-dessus, une suggestion est présentée à l’utilisateur, l’amenant à l’étape suivante de son flux de travail avec un seul onglet ou un seul clic. Les expériences exigeant que l’utilisateur se souvienne de déclencher la fonctionnalité n’ont pas été mises à l’échelle.
- Nous observons qu’avec les suggestions basées sur l’IA, le l’auteur du code devient de plus en plus un réviseur, et il est important de trouver un équilibre entre le coût de l’examen et la valeur ajoutée. Nous abordons généralement le compromis avec des objectifs de taux d’acceptation.
- Itérations rapides avec les expériences A/B en ligne sont essentielles, car les mesures hors ligne ne sont souvent que des approximations de la valeur utilisateur. En présentant nos fonctionnalités basées sur l’IA sur des outils internes, nous bénéficions grandement de la possibilité de lancer et d’itérer facilement, de mesurer les données d’utilisation et d’interroger directement les utilisateurs sur leur expérience via la recherche UX.
- Des données de haute qualité des activités des ingénieurs de Google à travers les outils logiciels, y compris les interactions avec nos fonctionnalités, est essentiel pour la qualité de notre modèle.
Nous observons à travers les fonctionnalités que son important d’optimiser la conversion de l’opportunité (principalement une activité de l’utilisateur, affichée en haut de l’entonnoir ci-dessous) à l’impact (assistance IA appliquée, en bas de l’entonnoir), tout en supprimant les goulots d’étranglement des étapes intermédiaires de l’entonnoir en tirant parti des améliorations de l’UX et du modèle.

Un entonnoir d’opportunités allant des actions SWE jusqu’à l’application réelle de suggestions basées sur le ML. Des opportunités sont perdues si la prédiction du modèle n’est pas suffisamment fiable, si le modèle ne répond pas ou répond trop tard, si la prédiction est médiocre, si l’utilisateur ne remarque pas la prédiction, etc. Nous utilisons l’UX et les améliorations de modèles pour récolter autant d’opportunités que possible.
Et après
Encouragés par nos succès jusqu’à présent, nous redoublons d’efforts pour apporter les derniers modèles de base (série Gemini) imprégnés des données des développeurs (dans le cadre de DIDACT, mentionné ci-dessus) pour alimenter les applications existantes et nouvelles de ML dans l’ingénierie logicielle de Google.
Dans l’ensemble du secteur, la complétion de code basée sur le ML a fourni un élan majeur aux développeurs de logiciels. Bien qu’il existe encore des possibilités d’améliorer la génération de code, nous nous attendons à ce que la prochaine vague d’avantages provienne de l’assistance ML dans un éventail plus large d’activités d’ingénierie logicielle, telles que les tests, la compréhension et la maintenance du code ; ce dernier étant particulièrement intéressant dans le contexte des entreprises. Ces opportunités éclairent notre propre travail en cours. Nous soulignons également deux tendances que nous observons dans l’industrie :
- L’interaction homme-machine a évolué vers le langage naturel comme modalité commune, et nous assistons à une évolution vers l’utilisation du langage comme interface pour les tâches d’ingénierie logicielle ainsi que comme passerelle vers les besoins d’information des développeurs de logiciels, le tout intégré dans les IDE.
- L’automatisation basée sur le ML de tâches à plus grande échelle, depuis le diagnostic d’un problème jusqu’à la résolution d’un correctif, a commencé à montrer les premières preuves de faisabilité. Ces possibilités sont motivées par les innovations dans agents et utilisation des outilsqui permettent la construction de systèmes utilisant un ou plusieurs LLM comme composant pour accomplir une tâche plus vaste.
Pour étendre les succès ci-dessus vers ces capacités de nouvelle génération, la communauté des praticiens et des chercheurs travaillant dans ce sujet bénéficierait de références communes pour aider à faire évoluer le domaine vers des tâches d’ingénierie pratiques. Jusqu’à présent, les benchmarks se sont concentrés principalement sur la génération de code (par exemple, HumanEval). Dans le cadre d’une entreprise, cependant, des tests de référence pour un plus large éventail de tâches pourraient s’avérer particulièrement utiles, par exemple les migrations de code et le débogage de production. Certains benchmarks, comme celui pour la résolution de bogues (par exemple, SWEBench), et des prototypes ciblant ces benchmarks (par exemple, de Cognition AI) ont été publiés. Nous encourageons la communauté à se rassembler pour suggérer davantage de références afin de couvrir un plus large éventail de tâches d’ingénierie logicielle.
Remerciements
Ce projet est le résultat du travail de nombreuses personnes de l’équipe Google Core Systems & Experiences et de Google Deepmind. Cet article a été co-écrit avec Boris Bokowski (directeur des outils de codage Google), Petros Maniatis (recherche), Ambar Murillo (UXR) et Alberto Elizondo (UXD). Une profonde gratitude va aux contributeurs aux différents reportages : Adam Husting, Ahmed Omran, Alexander Frmmgen, Ambar Murillo, Ayoub Kachkach, Brett Durrett, Chris Gorgolewski, Charles Sutton, Christian Schneider, Danny Tarlow, Damien Martin-Guillerez, David Tattersall, Elena Khrapko. , Evgeny Gryaznov, Franjo Ivancic, Fredde Ribeiro, Gabriela Surita, Guilherme Herzog, Henrik Muehe, Ilia Krets, Iris Chu, Juanjo Carin, Katja Grnwedel, Kevin Villela, Kristf Molnr, Lera Kharatyan, Madhura Dudhgaonkar, Marcus Revaj, Nimesh Ghelani, Niranjan Tulpule, Pavel Sychev, Siddhant Sanyam, Stanislav Pyatykh, Stoyan Nikolov, Ugam Kumar, Tobias Welp, Vahid Meimand, Vincent Nguyen, Yurun Shen et Zoubin Ghahramani. Merci à Tom Small pour la création de graphiques pour cet article. Merci également aux contributeurs DIDACT, réparation de construction, correctifs de lisibilité et résolution des commentaires de révision du code.