
Rendre les méthodes d’ensemble basées sur l’arbre décisionnel accessibles à l’informatique de périphérie – Bureau du blog du CTO
Dans l’ère à venir de l’informatique de périphérie, la capacité d’un dispositif de périphérie à effectuer une formation et une classification locales et rapides est de plus en plus nécessaire. En effet, qu’il s’agisse d’une application de santé sur un téléphone mobile, d’un capteur sur un réfrigérateur ou d’une caméra sur un robot aspirateur, un calcul local est souvent souhaité pour de nombreuses raisons, telles que la nécessité d’un temps de réponse rapide, l’amélioration des problèmes de sécurité, de confidentialité des données et même de rentabilité.
Que cela soit fait dans une fédération (c’est-à-dire, Federated Machine Learning) ou de manière centralisée, avoir une hétérogénéité, une connectivité limitée et des ressources matérielles limitées pour de tels appareils est un défi permanent que nous devons relever. En fait, on est souvent confronté à des exigences contradictoires où un périphérique périphérique doit effectuer localement une quantité substantielle de calcul, de stockage et de communication tout en respectant des contraintes de ressources telles qu’une mémoire limitée, une connectivité réseau et un calcul. Cela est souvent dû à des contraintes de temps ou de puissance et à des quantités croissantes de données et d’informations disponibles.
Dans cet article de blog, nous nous concentrons sur la formation locale efficace en termes de calcul et de mémoire (c’est-à-dire sur l’appareil) et la classification par des méthodes d’ensemble basées sur un arbre de décision, qui sont la norme de facto pour les données tabulaires. Pour fournir un contexte supplémentaire, nous vous invitons à consulter notre récent article de blog traitant des techniques de réduction de la bande passante pour l’apprentissage automatique fédéré.
Méthodes d’ensemble basées sur un arbre de décision
En effet, les méthodes d’ensemble basées sur des arbres, telles que Random Forest (RF) et XGBoost, sont souvent utilisées pour classer les données tabulaires en raison de leur robustesse, de leur facilité d’utilisation et de leurs propriétés de généralisation. À leur tour, ces tâches de classification sont couramment utilisées comme sous-programme dans de nombreux domaines d’application, tels que la finance, la détection des fraudes, les soins de santé et la détection des intrusions. Par conséquent, les compromis efficacité et précision-utilité de ces méthodes sont d’une importance majeure.
Concentrons-nous spécifiquement sur RF et XGBoost et comprenons leurs avantages :
- RF, sans doute la méthode d’ensachage la plus populaire, développe chaque arbre de décision en utilisant un sous-échantillon aléatoire des données, ce qui donne des arbres différents et faiblement corrélés. Ensuite, un vote majoritaire est utilisé pour déterminer le classement. Les RF présentent plusieurs avantages, notamment la robustesse, la formation rapide, la capacité de traiter des ensembles de données déséquilibrés, la sélection de fonctionnalités intégrées, la gestion des fonctionnalités manquantes, catégorielles et continues, et l’interprétabilité pour une analyse humaine avancée ou chaque fois que la réglementation l’exige.
- XGBoost, un algorithme de boost bien connu et populaire, développe un petit arbre de décision (par exemple, avec 832 nœuds terminaux) à chaque itération. Chacun de ces arbres est conçu pour réduire les erreurs de classification des arbres précédents. XGBoost partage la plupart des avantages de la RF et atteint souvent une plus grande précision en raison de sa polarisation contrôlée.
Néanmoins, ces méthodes introduisent également certains inconvénients liés aux ressources :
- Les RF ont tendance à être liés à la mémoire et plus lents à la classification. De plus, en raison de leur grande empreinte mémoire, les RF ne peuvent souvent pas être déployées sur des appareils périphériques avec une mémoire limitée, où les tâches de classification sont souvent souhaitées.
- Les modèles XGBoost nécessitent souvent moins de mémoire que les RF, mais ils sont gourmands en ressources de calcul, ce qui ralentit la formation.
Dans cet article de blog, nous abordons les inconvénients de la consommation de ressources de RF et de XGBoost. En particulier, nous introduisons une nouvelle approche hybride qui hérite des bonnes propriétés des méthodes de bagging et de boosting avec des performances d’apprentissage automatique (ML) comparables tout en étant nettement plus économe en ressources.
Redondance dans les jeux de données
Il est de notoriété publique que la consommation de ressources des modèles ML est fortement corrélée à la taille de l’ensemble de données utilisé pour leur formation. Ainsi, la réduction de la taille du jeu de données est souhaitable. En conséquence, nous voudrions soulever les questions suivantes :
- Toutes les instances de données d’un ensemble de données sont-elles d’une importance identique pour la formation d’un modèle d’ensemble arborescent ?
- Si non, comment différencier les instances de données lors de la formation pour économiser les ressources ? Comment cela affecterait-il la classification?
En effet, souvent, un jeu de données contient de nombreuses instances de données qui sont plus simples (par exemple, 90 %) dans le sens où elles sont facilement reconnaissables et donc faciles à classer ; et des instances de données rares ou plus uniques et donc plus difficiles à classer.
Intuitivement, si une telle différenciation est disponible avant la formation, on devrait pouvoir utiliser ces connaissances pour économiser des ressources sans impact significatif sur la précision. L’une de ces idées consiste à utiliser moins d’instances de données « faciles » pendant la formation. Le défi est de savoir comment produire de tels schémas et le faire de manière efficace.
Modèle de détection d’anomalies économe en ressources RADE
RADE cible le cas d’utilisation de la détection supervisée d’anomalies ; à savoir, l’ensemble de données n’a que deux classes où la plupart des instances sont normales ou bénignes (par exemple, 99%).

RADE exploite l’observation ci-dessus de la manière suivante : il construit d’abord un petit modèle (à gros grains) en utilisant l’ensemble de données complet. Il utilise ensuite ce modèle pour classer toutes les instances de données utilisées pour son apprentissage. Les instances correctement classées avec une confiance élevée sont étiquetées comme faciles (souvent, la plupart des instances normales), tandis que toutes les autres instances sont étiquetées comme difficiles (souvent, la plupart des instances anormales)
Comme l’illustre la figure 1, RADE introduit une architecture de haut niveau qui peut être utilisée avec différents modèles de classification tant que le modèle à gros grains fournit un niveau de confiance de classification significatif avec sa classification.
Intuitivement, puisque le modèle à gros grains est suffisant pour classer correctement les requêtes faciles, il ne nous reste que des requêtes difficiles. En utilisant ceux-ci, nous construisons deux modèles experts (à grain fin) qui sont conçus pour traiter deux cas différents concernant le résultat de classification du modèle à grain grossier : le modèle à grain fin 1 est responsable de (faible confiance) Normal
classifications et modèle 2 à grain fin pour les classifications d’anomalies (de faible confiance). Ces modèles peuvent avoir une empreinte mémoire plus importante que le modèle à gros grains, mais nettement inférieure à celle des modèles arborescents monolithiques.
Efficacité de la formation: Comme décrit, RADE est formé en deux phases. Tout d’abord, le modèle à gros grains est formé à l’aide de l’ensemble de données complet. Cette phase d’apprentissage est relativement rapide puisque nous utilisons un petit modèle. Ensuite, nous classifions l’ensemble de données d’entraînement à l’aide du modèle à grain grossier et, sur la base des classifications et des niveaux de confiance résultants, produisons deux sous-ensembles de données pour l’entraînement des modèles à grain fin. Cette phase de formation est également relativement rapide puisque nous formons chaque modèle à grain fin avec seulement un sous-ensemble des données de formation (par exemple, 10%).
Efficacité du classement: la classification du RADE comporte également deux phases. Tout d’abord, une instance est classée par le modèle à gros grains. Si la confiance de classification qui en résulte est élevée (par exemple, 0,9), alors la classification est terminée. Sinon, la requête est transmise pour reclassification par l’un des modèles à grain fin selon le résultat de classification du modèle à grain grossier. Cela signifie que le temps de classification de RADE est égal à une moyenne pondérée des temps de classification : les classifications qui sont servies uniquement par le modèle à gros grains et celles qui sont servies à la fois par le modèle à gros grains et un modèle à grains fins. Intuitivement, puisque le but est
pour ne servir la plupart des requêtes que par le modèle à gros grains (par exemple, 90 %), le temps de classification moyen devrait s’améliorer de manière significative par rapport aux modèles monolithiques standard.
Modèle de classification multiclasse Duet économe en ressources
RADE est conçu pour la classification binaire et utilise donc deux modèles à grain fin. L’extension de l’architecture de RADE, telle quelle, pour les cas d’utilisation de classification multi-classes n’est pas une solution évolutive car elle nécessiterait K modèles à grain fin pour K classes, et donc une nouvelle architecture est nécessaire.
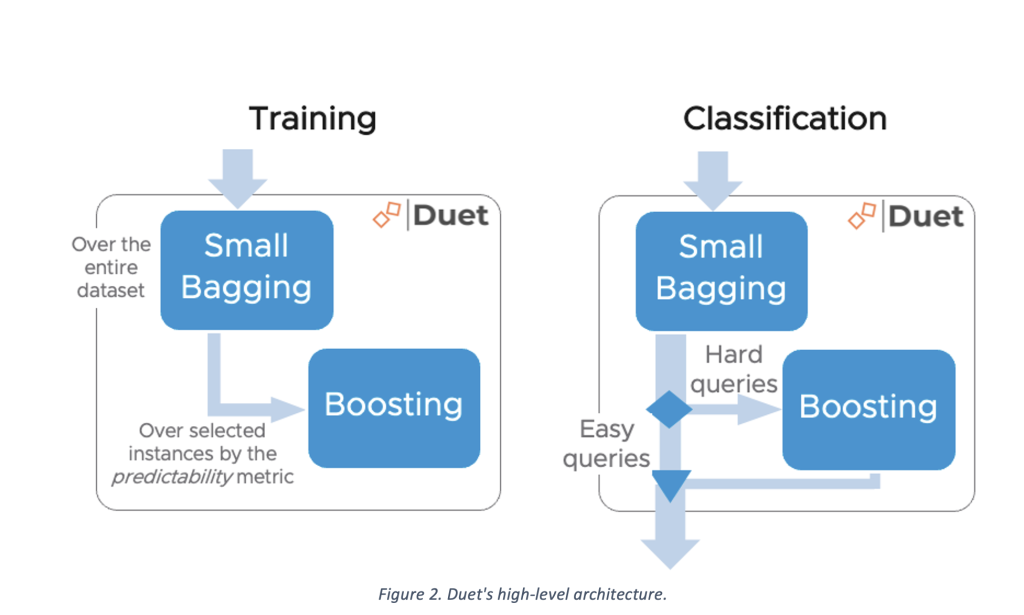
À cette fin, nous avons développé Duet. Duet suit les principes de RADE, c’est-à-dire qu’il utilise un modèle à gros grains qui est formé sur l’ensemble de données et classe les requêtes faciles. Cependant, contrairement à RADE, Duet n’utilise qu’un seul classificateur à granularité fine qui est formé sur un sous-ensemble de l’ensemble de données de formation et classe les requêtes dures (à faible confiance).
L’architecture de haut niveau de Duet est illustrée à la figure 2. Elle utilise essentiellement deux classificateurs : un petit classificateur d’ensachage (RF) qui offre une confiance de classification significative, une variance contrôlée et une limite de mémoire, et un classificateur d’amplification (XGBoost) qui offre un biais et un biais contrôlés. est lié au calcul. Dans l’ensemble, Duet introduit un compromis de performance système/ML différent et souvent meilleur par rapport aux classificateurs monolithiques.
La question principale est de savoir comment déterminer le sous-ensemble des données d’apprentissage pour le classificateur boostant.
L’utilisation de la métrique de confiance comme dans RADE est insuffisante dans ce cas puisque nous avons un problème multidimensionnel. Donc, à la place, nous utilisons le vecteur de distribution de probabilité de classe (par le modèle à gros grains) pour déterminer à quel point une instance est vitale pour la procédure de formation.
Considérez deux résultats de classification avec une confiance de classification identique (top-1) pour une tâche de classification avec six classes. Le premier avec une distribution de classe de probabilités (presque) égales sur deux classes (par exemple, [0.5, 0.5, 0, 0, 0, 0]), et la seconde avec une probabilité plus élevée pour la classe correcte et des probabilités beaucoup plus faibles pour toutes les classes restantes (par exemple, [0.5, 0.1, 0.1, 0.1, 0.1, 0.1]). De toute évidence, la première requête est plus difficile et peut être plus bénéfique pour l’entraînement du classificateur boostant.
Pour capturer cette propriété, nous avons défini une nouvelle métrique prévisibilité qui est donné par la fonction de distance euclidienne qui mesure la distance entre le vecteur de distribution de probabilité de classe résultant et le vecteur de distribution parfait par rapport à la véritable étiquette de l’instance. Un vecteur de distribution parfait devrait avoir une probabilité de un dans la bonne étiquette (c’est-à-dire la classe).
Notez que la prévisibilité est un spécifique métrique pour un étant donné classificateur d’ensachage formé et un ensemble de données de formation et constitue donc une étape intégrée dans le processus de formation de Duet. Aussi, en utilisant
la prévisibilité est différente des méthodes d’échantillonnage qui ne dépendent que des propriétés de l’ensemble de données (par exemple, l’échantillonnage stratifié, qui préserve le pourcentage d’instances par classe).
Potentiel et matériaux supplémentaires
Les principes de conception ci-dessus peuvent potentiellement être adaptés à d’autres domaines ML. Alors que Duet utilise principalement la mesure de prévisibilité pour réduire le coût de calcul des procédures de formation et de classification, on peut utiliser la mesure de prévisibilité pour réduire la taille d’un ensemble de données de formation et donc réduire les coûts de stockage et de communication.
De plus, RADE et Duet peuvent potentiellement être adaptés pour des environnements d’apprentissage distribués et fédérés. Par exemple, les participants peuvent former conjointement un modèle à grain grossier, puis utiliser ce modèle pour choisir un ou plusieurs sous-ensembles à partir de leurs ensembles de données locaux, et enfin former un ou des modèles globaux à grain fin à l’aide de ces sous-ensembles.
Le défi ici est de déterminer les critères selon lesquels un participant choisit son sous-ensemble. Par exemple, une approche avancée consisterait à utiliser un calcul sécurisé pour collecter des informations statistiques sur les données de formation globales. Ces statistiques peuvent entraîner une meilleure sélection de sous-ensembles par chaque participant qui, dans l’ensemble, a une valeur de formation plus élevée pour la formation distribuée/fédérée du ou des modèles à granularité fine.
Si vous souhaitez en savoir plus, notamment sur notre utilisation des seuils de confiance, de la prévisibilité et des résultats d’évaluation multiples sur des serveurs et des appareils à ressources limitées tels qu’un Raspberry Pi, consultez les articles suivants présentant RADE et Duet.
Si vous souhaitez mettre la main sur le code, RADE et Duet sont implémentés en tant que classificateurs sci-kit et sont accessibles au public sur GitHub.